Guide to deploying TeskaLabs LogMan.io for partners¶
Preimplementation analysis¶
Every delivery should begin with a preimplementation analysis, which lists all the log sources, that should be connected to LogMan.io. Outcome of the analysisis the spreadsheet, where each lane describes one log source, the way how logs are gathered (reading files, log forwarding to destination port etc.), who is responsible for the log source from the customer perspective and the estimation when the log source should be connected. See the following picture:

In the picture, there are two more columns that are not part of the preimplementation analysis and that are filled later when the implementation takes place (kafka topic & dataset). Fore more information, see Event lanes section below.
It MUST BE defined, which domain (URL) will be used to host the LogMan.io.
The customer or partner themselves SHOULD provide appropriate HTTPS SSL certificates (see nginx below), e.g. using Let's Encrypt or other Certification authority.
LogMan.io cluster and collector servers¶
Servers¶
By the end of the preimplementation analysis, it should be clear how big the volume of gathered logs (in events or log messages per second, EPS for short) should be. The logs are always gathered from the customer's infrastructure with at least one server dedicated to collecting logs (aka log collector).
When it comes to LogMan.io cluster, there are three ways:
- LogMan.io cluster is deployed to the customer's infrastructure to physical and/or virtual machines (on-premise)
- LogMan.io cluster is deployed at the partner's infrastructure and available for more customers, where each customer is assigned a single
tenant(SoC, SaaS etc.)
See Hardware specification section for more information about the physical servers' configuration.
Cluster architecture¶
In either cluster way, there SHOULD be at least one server (for PoCs) or at least three servers (for deployment) available for the LogMan.io cluster. If the cluster is deployed to the customer's infrastructure, the servers may also act as the collector servers, so there is no need to have a dedicated collector server in this case. The three server architecture may consists of three similar physical servers, or two physical servers and one small arbitrary virtual machine.
A smaller or non-critical deployments are possible on the single machine configuration.
For more information of the LogMan.io cluster organization, see Cluster architecture section.
Data storage¶
Every physical or non-arbiter server in LogMan.io cluster should have enough available disk storage to hold the data for the requested time period from the preimplementation analysis.
There should be at least one fast (for current or one-day log messages and Kafka topics) and one slower (for older data, metadata and configurations) data storage mapped to /data/ssd and /data/hdd.
Since all LogMan.io services run as Docker containers, /var/lib/docker folder should be also mapped to one of those storage.
For detailed information about the disk storage organization, mount etc. please see Data Storage section.
Installation¶
The RECOMMENDED operating system is Linux Ubuntu 22.04 LTS or newer. Alternatives are Linux RedHat 8 and 7, CentOS 7.
The hostnames of the LogMan.io servers in the LogMan.io cluster should follow the notation lm01, lm11 etc.
If separate collector servers are used (see above) there is no requirement for their hostname naming.
If TeskaLabs is part of the delivery, there should be a tladmin user created with sudoer permissions.
On every server (both LogMan.io cluster and Collector), there should be git, docker and docker-compose installed.
Please refer to Manual installation for a comprehensive guide.
All services are then created and started via docker-compose up -d command from the folder the site repository is cloned to (see the following section):
$ cd /opt/site-tenant-siterepository/lm11
$ docker-compose up -d
The Docker credentials are provided to the partner by TeskaLabs' team.
Site repository and configuration¶
Every partner is given access to TeskaLabs GitLab to manage the configurations for deployments there, which is a recommended way to store configurations for future consultations with TeskaLabs. However, every partner may also use their own GitLab or any other Git repository and provide TeskaLabs' team with appropriate (at least read-only) accesses.
Every deployment to every customer should have a separate site repository, regardless if the entire LogMan.io cluster is installed or only collector servers are deployed. The structure of the site repository should look as follows:
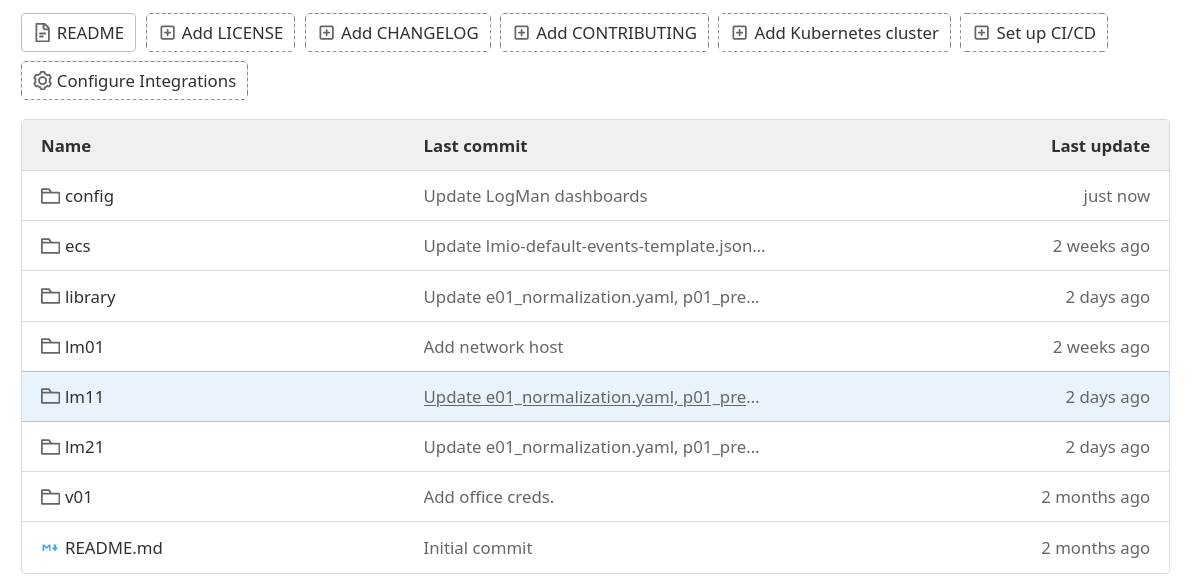
Each server node (server) should have a separate subfolder at the top of the GitLab repository.
Next, there should be a folder with LogMan.io library, that contains declarations for parsing, correlating etc. groups, config, that contains configuration of the Discover screen in UI and dashboards and ecs folder with index templates for ElasticSearch.
Every partner is given access to a reference site repository with all the configurations including parsers and discover settings ready.
ElasticSearch¶
Each node in the LogMan.io Cluster should contain at least one ElasticSearch master node, one ElasticSearch data_hot node, one ElasticSearch data_warm node and one ElasticSearch data_cold node.
All the ElasticSearch nodes are deployed via Docker Compose and are part of the site/configuration repository.
Arbitrary nodes in the cluster contain only one ElasticSearch master node.
If one server architecture is used, the replicas in ElasticSearch should be set to zero (this will also be provided after the consultation with TeskaLabs). For illustration, see the following snipplet from Docker Compose file to see how ElasticSearch hot node is deployed:
lm21-es-hot01:
network_mode: host
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.2
depends_on:
- lm21-es-master
environment:
- network.host=lm21
- node.attr.rack_id=lm21 # Or datacenter name. This is meant for ES to effectively and safely manage replicas
# For smaller installations -> a hostname is fine
- node.attr.data=hot
- node.name=lm21-es-hot01
- node.roles=data_hot,data_content,ingest
- cluster.name=lmio-es # Basically "name of the database"
- cluster.initial_master_nodes=lm01-es-master,lm11-es-master,lm21-es-master
- discovery.seed_hosts=lm01:9300,lm11:9300,lm21:9300
- http.port=9201
- transport.port=9301 # Internal communication among nodes
- "ES_JAVA_OPTS=-Xms16g -Xmx16g -Dlog4j2.formatMsgNoLookups=true"
# - path.repo=/usr/share/elasticsearch/repo # This option is enabled on demand after the installaton! It's not part of the initial setup (but we have it here because it's a workshop)
- ELASTIC_PASSWORD=$ELASTIC_PASSWORD
- xpack.security.enabled=true
- xpack.security.transport.ssl.enabled=true
...
For more information about ElasticSearch including the explanation of hot (recent, one-day data on SSD), warm (older) and cold nodes, please refer to ElasticSearch Setting section.
ZooKeeper & Kafka¶
Each server node in the LogMan.io Cluster should contain at least one ZooKeeper and one Kafka node. ZooKeeper is a metadata storage available in the entire cluster, where Kafka stores information about topic consumers, topic names etc., and where LogMan.io stores the current library and config files (see below).
The Kafka and ZooKeeper setting can be copied from the reference site repository and consulted with TeskaLabs developers.
Services¶
The following services should be available at least on one of the LogMan.io nodes and they include:
nginx(webserver with HTTPS certificate, see the reference site repository)influxdb(metric storage, see InfluxDB Setting)mongo(database for credentials of users, sessions etc.)telegraf(gathers telemetry metrics from the infrastructure, burrow and ElasticSearch and sends them to InfluxDB, it should be installed on every server)burrow(gathers telemetry metrics from Kafka and sends them to InfluxDB)seacat- auth(TeskaLabs SeaCat Auth is a OAuth service, that stores its data to mongo)asab-library(manages thelibrarywith declarations)asab-config(manages theconfigsection)lmio-remote-control(monitors other microservices likeasab-config)lmio-commander(uploads thelibraryto ZooKeeper)lmio-dispatcher(dispatches data fromlmio-eventsandlmio-othersKafka topics to ElasticSearch, it should run in at least three instances on every server)
For more information about SeaCat Auth and its management part in LogMan.io UI, see TeskaLabs SeaCat Auth documentation.
For information on how to upload the library from the site repository to ZooKeeper, refer to LogMan.io Commander guide.
UI¶
The following UIs should be deployed and made available via nginx. First implementation should always be discussed with TeskaLabs' developers.
LogMan.io UI(see LogMan.io User Interface)Kibana(discover screen, visualizations, dashboards and monitoring on top of ElasticSearch)Grafana(telemetry dashboards on top of data from InfluxDB)ZooKeeper UI(management of data stored in ZooKeeper)
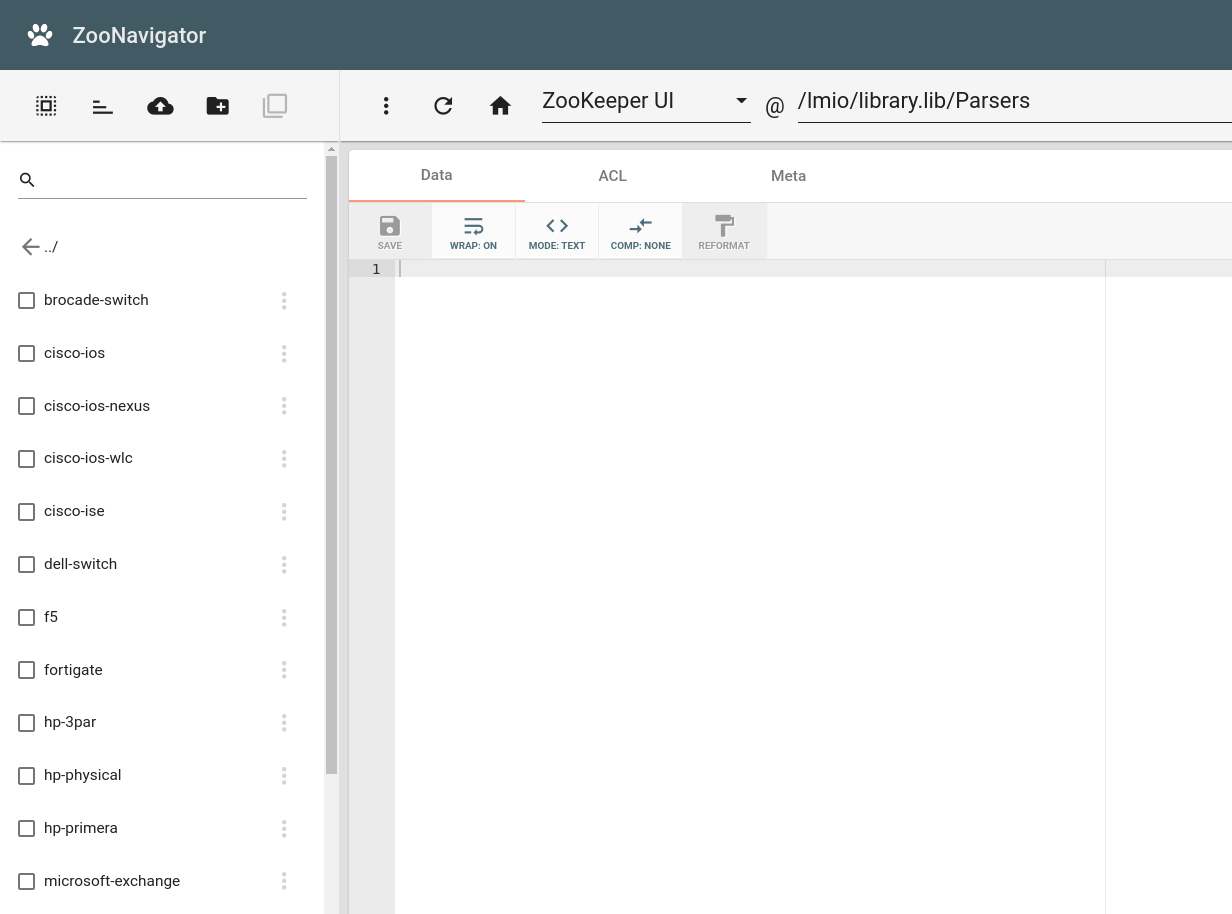
The following picture shows the Parsers from the library imported to ZooKeeper in ZooKeeper UI:
LogMan.io UI Deployment¶
Deployment of LogMan.io UI is partially semi-automatic process when set up correctly. So there are several steps to ensure the safe UI deployment:
- Deployment artifact of the UI should be pulled via
azuresite repository provided to the partner by TeskaLabs' developers. Information about where the particular UI application is stored can be obtained from CI/CD image of the application repository. - It is recommended to use
taggedversions, but there can be situations whenmasterversion is desired. Information how to set it up can be found indocker-compose.yamlfile of the reference site repository. - UI application have to be aligned with the services to ensure the best performance (usually latest
tagversions). If uncertain, contact TeskaLabs' developers.
Creating the tenant¶
Each customer is assigned one or more tenants.
Tenants are lowercase ASCII names, that tag the data/logs belonging to the user and store each tenant's data in a separate ElasticSearch index.
All event lanes (see below) are also tenant specific.
Create the tenant in SeaCat Auth using LogMan.io UI¶
In order to create the tenant, log into the LogMan.io UI with the superuser role, which can be done through the provisioning. For more information about provisioning, please refer to Provisioning mode section of the SeaCat Auth documentation.
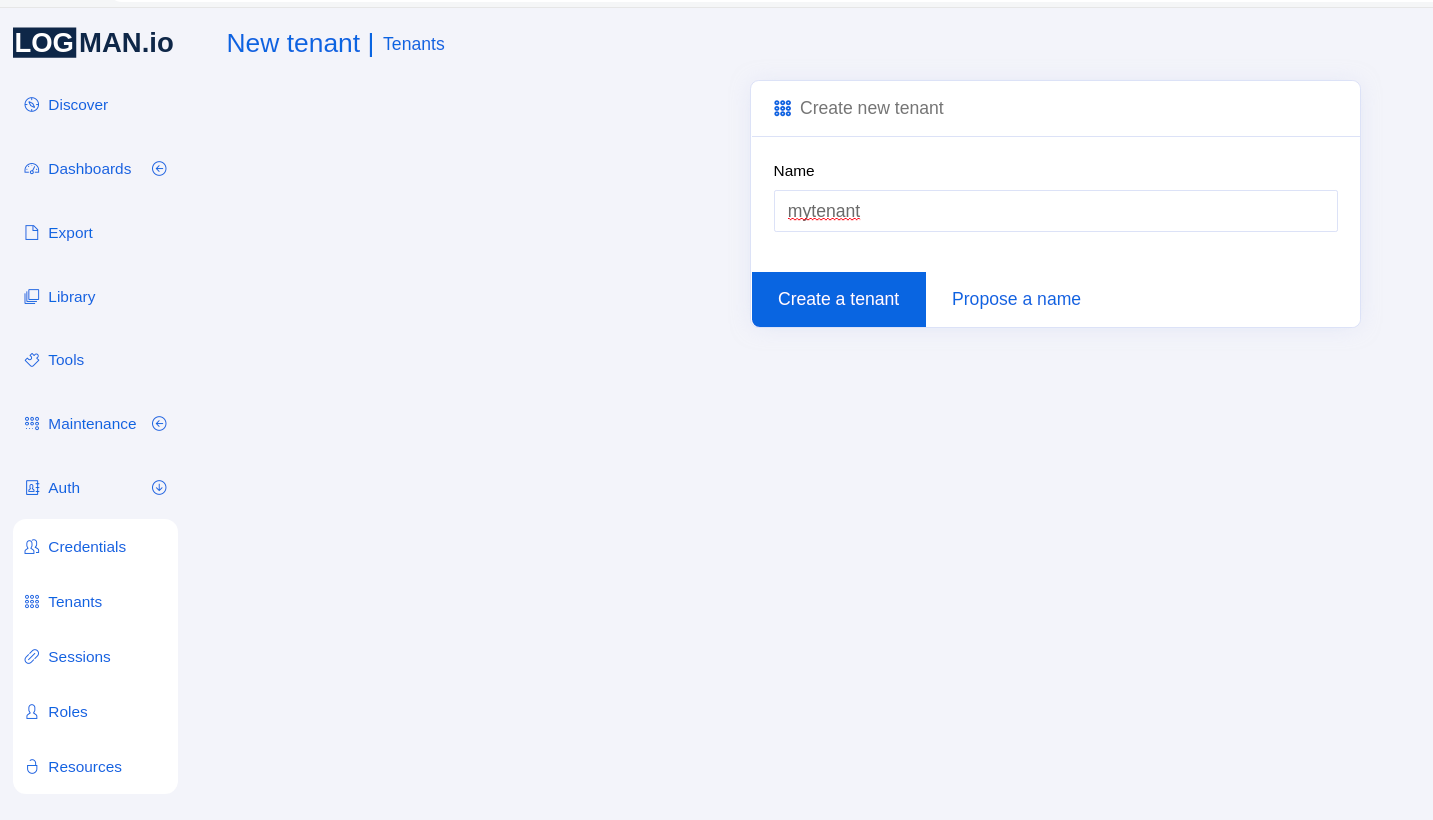
In LogMan.io UI, navigate to the Auth section in the left menu and select Tenants.
Once there, click on Create tenant option and write the name of the tenant there.
Then click on the blue button and the tenant should be created:
After that, go to Credentials and assign the newly created tenant to all relevant users.
ElasticSearch indices¶
In Kibana, every tenant should have index templates for lmio-tenant-events and lmio-tenant-others indices, where tenant is the name of the tenant (refer to the reference site repository provided by TeskaLabs).
The index templates can be inserted via Kibaba's Dev Tools from the left menu.
After the insertion of the index templates, ILM (index life cycle management) policy and the first indices should be manually created, exactly as specified in the ElasticSearch Setting guide.
Kafka¶
There is no specific tenant creation setting in Kafka, except the event lanes below.
However, always make sure the lmio-events and lmio-others topics are created properly.
The following commands should be run in the Kafka container (f. e.: docker exec -it lm11_kafka_1 bash):
# LogMan.io
/usr/bin/kafka-topics --zookeeper lm11:2181 --create --topic lmio-events --replication-factor 1 --partitions 6
/usr/bin/kafka-topics --zookeeper lm11:2181 --create --topic lmio-others --replication-factor 1 --partitions 6
/usr/bin/kafka-topics --zookeeper lm11:2181 --alter --topic lmio-events --config retention.ms=86400000
/usr/bin/kafka-topics --zookeeper lm11:2181 --alter --topic lmio-others --config retention.ms=86400000
# LogMan.io+ & SIEM
/usr/bin/kafka-topics --zookeeper lm11:2181 --create --topic lmio-events-complex --replication-factor 1 --partitions 6
/usr/bin/kafka-topics --zookeeper lm11:2181 --create --topic lmio-lookups --replication-factor 1 --partitions 6
Each Kafka topic should have at least 6 partitions (that can be automatically used for parallel consuming), which is the appropriate number for most of the deployments.
Important note¶
The following section describes the connection of event lanes to LogMan.io. The knowledge about LogMan.io architecture from the documentation is mandatory.
Event lanes¶
Event lanes in LogMan.io define how logs are sent to the cluster. Each event lane is specific for the collected source, hence one row in the preimplementation analysis table should correspond to one event lane. Each event lane consists of one lmio-collector service, one lmio-ingestor service and one or more instances of lmio-parser service.
Collector¶
LogMan.io Collector should run on the collector server or on one or more LogMan.io servers, if they are part of the same internal network. The configuration sample is part of the reference site repository.
LogMan.io Collector is able to, via YAML configuration, open a TCP/UDP port to obtain logs from, read files, open a WEC server, read from Kafka topics, Azure accounts and so on. The comprehensive documentation is available here: LogMan.io Collector
The following configuration sample opens 12009/UDP port on the server the collector is installed to, and redirects the collected data via WebSocket to the lm11 server to port 8600, where lmio-ingestor should be running:
input:Datagram:UDPInput:
address: 0.0.0.0:12009
output: WebSocketOutput
output:WebSocket:WebSocketOutput:
url: http://lm11:8600/ws
tenant: mytenant
debug: false
prepend_meta: false
The url is either the hostname of the server and port of the Ingestor, if Collector and Ingestor are deployed to the same server, or URL with https://, if collector server outside of the internal network is used. It is then necessary to specify HTTPS certificates, please see the output:WebSocket section in the LogMan.io Collector Outputs guide for more information.
The tenant is the name of the tenant the logs belong to. The tenant name is then automatically propagated to Ingestor and Parser.
Ingestor¶
LogMan.io Ingestor takes the log messages from Collector along with metadata and stores them in Kafka in a topic, that begins with collected-tenant- prefix, where tenant is the tenant name the logs belong to and technology the name of the technology the data are gathered from like microsoft-windows.
The following sections in the CONF files are necessary to be always set up differently for each event lane:
# Output
[pipeline:WSPipeline:KafkaSink]
topic=collected-tenant-technology
# Web API
[web]
listen=0.0.0.0 8600
The port in the listen section should match the port in the Collector YAML configuration (if the Collector is deployed to the same server) or the setting in nginx (if the data are collected from a collector server outside of the internal network). Please refer to the reference site repository provided by TeskaLabs' developers.
Parser¶
The parser should be deployed in more instances to scale the performance. It parses the data from original bytes or strings to a dictionary in the specified schema like ECS (ElasticSearch Schema) or CEF (Common Event Format), while using a parsing group from the library loaded in ZooKeeper. It is important to specify the Kafka topic to read from, which is the same topic as specified in the Ingestor configuration:
[declarations]
library=zk://lm11:2181/lmio/library.lib
groups=Parsers/parsing-group
raw_event=log.original
# Pipeline
[pipeline:ParsersPipeline:KafkaSource]
topic=collected-tenant-technology
group_id=lmio_parser_collected
auto.offset.reset=smallest
Parsers/parsing-group is the location of the parsing group from the library loaded in ZooKeeper through LogMan.io Commander. It does not have to exist at the first try, because all data are then automatically send to lmio-tenant-others index. When the parsing group is ready, the parsing takes place and the data can be seen in the document format in lmio-tenant-events index.
Kafka topics¶
Before all three services are started via docker-compose up -d command, it is important to check the state of the specific collected-tenant-technology Kafka topic (where tenant is the name of the tenant and technology is the name of the connected technology/device type). In the Kafka container (f. e.: docker exec -it lm11_kafka_1 bash), the following commands should be run:
/usr/bin/kafka-topics --zookeeper lm11:2181 --create --topic collected-tenant-technology --replication-factor 1 --partitions 6
/usr/bin/kafka-topics --zookeeper lm11:2181 --alter --topic collected-tenant-technology --config retention.ms=86400000
Parsing groups¶
For most common technologies, TeskaLabs have already prepared the parsing groups to ECS schema. Please get in touch with TeskaLabs developers. Since all parsers are written in the declarative language, all parsing groups in the library can be easily adjusted. The name of the group should be the same as the name of the dataset attribute written in the parser groups' declaration.
For more information about our declarative language, please refer to the official documentation: SP-Lang
After the parsing group is deployed via LogMan.io Commander, the appropriate Parser(s) should be restarted.
Deployment¶
On the LogMan.io servers, simply run the following command in the folder the site- repository is cloned to:
docker-compose up -d
The collection of logs can be then checked in the Kafka Docker container via Kafka's console consumer:
/usr/bin/kafka-console-consumer --bootstrap-server lm11:9092 --topic collected-tenant-technology --from-beginning
The data are pumped in Parser from collected-tenant-technology topic to lmio-events or lmio-others topic and then in Dispatcher (lmio-dispatcher, see above) to lmio-tenant-events or lmio-tenant-others index in ElasticSearch.
SIEM¶
SIEM part should be now always discussed with TeskaLabs's developers, who will provide first correlation rules and entries to configuration files and Docker Compose. The SIEM part consists mainly of different lmio-correlators instances and lmio-watcher.
For more information, see the LogMan.io Correlator section.