Parsing tutorial¶
The complete parsing process requires parser, mapping, and enricher declarations. This tutorial breaks down creating declarations step-by-step. Visit the LogMan.io Parsec documentation for more on the Parsec microservice.
Before you start
SP-Lang
Parsing declarations are written in TeskaLabs SP-Lang. For more details about parsing expressions, visit the SP-Lang documentation.
Declarations
For more information on specific types of declarations, see:
Sample logs¶
This example uses this set of logs collected from various Sophos SG230 devices:
<181>2023:01:12-13:08:45 asgmtx httpd: 212.158.149.81 - - [12/Jan/2023:13:08:45 +0100] "POST /webadmin.plx HTTP/1.1" 200 2000
<38>2023:01:12-13:09:09 asgmtx sshd[17112]: Failed password for root from 218.92.0.190 port 56745 ssh2
<38>2023:01:12-13:09:20 asgmtx sshd[16281]: Did not receive identification string from 218.92.0.190
<38>2023:01:12-13:09:20 asgmtx aua[2350]: id="3005" severity="warn" sys="System" sub="auth" name="Authentication failed" srcip="43.139.111.88" host="" user="login" caller="sshd" reason="DENIED"
These logs are using the syslog format described in RFC 5424.
Logs can be typically separated into two parts: the header and the body. The header is anything preceding the first colon after the timestamp. The body is the rest of the log.


Parsing strategy¶
The Parsec interprets each declaration alphabetically by name, so naming order matters. Within each declaration, the parsing process follows the order that you write the expressions in like steps.
A parsing sequence can include multiple parser declarations, and also needs a mapping declaration and an enricher declaration. In this case, create these declarations:
- First parser declaration: Parse the syslog headers
- Second parser declaration: Parse the body of the logs as the message.
- Mapping declaration: Rename fields
- Enricher declaration: Add metadata (such as the dataset name) and compute syslog facility and severity from priority
As per naming conventions, name these files:
- 10_parser_header.yaml
- 20_parser_message.yaml
- 30_mapping_ECS.yaml
- 40_enricher.yaml
Remember that declarations are interpreted in alphabetical order, in this case by the increasing numeric prefix. Use prefixes such as 10, 20, 30, etc. so you can add a new declaration between existing ones later without renaming all of files.
1. Parsing the header¶
This is the first parser declaration. The subsequent sections break down and explain each part of the declaration.
---
define:
type: parser/parsec
parse:
!PARSE.KVLIST
# PRI part
- '<'
- PRI: !PARSE.DIGITS
- '>'
# Timestamp
- TIMESTAMP: !PARSE.DATETIME
- year: !PARSE.DIGITS # year: 2023
- ':'
- month: !PARSE.MONTH { what: 'number' } # month: 01
- ':'
- day: !PARSE.DIGITS # day: 12
- '-'
- hour: !PARSE.DIGITS # hour: 13
- ':'
- minute: !PARSE.DIGITS # minute: 08
- ':'
- second: !PARSE.DIGITS # second: 45
- !PARSE.UNTIL ' '
# Hostname and process
- HOSTNAME: !PARSE.UNTIL ' ' # asgmtx
- PROCESS: !PARSE.UNTIL ':'
# Message
- !PARSE.SPACES
- MESSAGE: !PARSE.CHARS
Log headers¶
The syslog headers are in the format:
<PRI>TIMESTAMP HOSTNAME PROCESS.NAME[PROCESS.PID]:

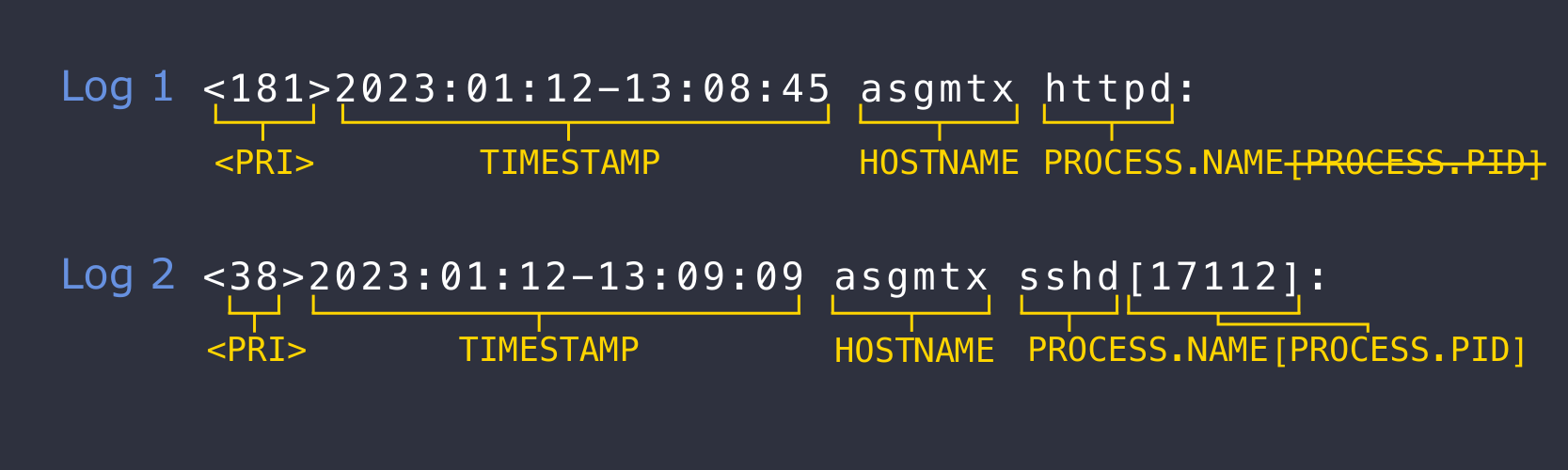
Important: Log variance
Notice that PROCESS.PID in the square brackets is not present in the first log's header. To accomodate the discrepancy, the parser will need a way to handle the possibility of PROCESS.PID being either present or absent. This is addressed later in the tutorial.
Parsing the PRI¶
First, parse the PRI, which is enclosed by < and > characters, with no space in between.
How to parse <PRI>, as seen in the first parser declaration:
!PARSE.KVLIST
- !PARSE.EXACTLY { what: '<' }
- PRI: !PARSE.DIGITS
- !PARSE.EXACTLY { what: '>' }
Expressions used:
!PARSE.EXACTLY: Parsing the characters<and>!PARSE.DIGITS: Parsing the numbers (digits) of the PRI
!PARSE.EXACTLY shortcut
The !PARSE.EXACTLY expression has a syntactic shortcut because it is so commonly used. Instead of including the whole expression, PARSE.EXACTLY { what: '(character)' } can be shortened to '(character').
So, the above parser declaration can be shortened to:
!PARSE.KVLIST
- '<'
- PRI: !PARSE.DIGITS
- '>'
Parsing the timestamp¶
The unparsed timestamp format is:
yyyy:mm:dd-HH:MM:SS
2023:01:12-13:08:45
Parse the timestamp with the !PARSE.DATETIME expression.
As seen in the first parser declaration:
# 2023:01:12-13:08:45
- TIMESTAMP: !PARSE.DATETIME
- year: !PARSE.DIGITS # year: 2023
- ':'
- month: !PARSE.MONTH { what: 'number' } # month: 01
- ':'
- day: !PARSE.DIGITS # day: 12
- '-'
- hour: !PARSE.DIGITS # hour: 13
- ':'
- minute: !PARSE.DIGITS # minute: 08
- ':'
- second: !PARSE.DIGITS # second: 45
- !PARSE.UNTIL { what: ' ', stop: after }
Parsing the month:
The !PARSE.MONTH expression requires you to specify the format of the month in the what parameter. The options are:
'number'(used in this case) which accepts numbers 01-12'short'for shortened month names (JAN, FEB, etc.)'full'for full month names (JANUARY, FEBRUARY, etc.)
Parsing the space:
The space at the end of the timestamp also needs to be parsed. Using the !PARSE.UNTIL expression parses everything until the space character (' '), stopping after the space, as defined (stop: after).
!PARSE.UNTIL shortcuts and alternatives
!PARSE.UNTIL has the syntactic shortcut:
- !PARSE.UNTIL ' '
- !PARSE.UNTIL { what: ' ', stop: after }
Alternatively, you can choose an expression that specifically parses one or multiple spaces, respectively:
- !PARSE.SPACE
or
- !PARSE.SPACES
At this point, the sequence of characters <181>2023:01:12-13:08:45 (including the space at the end) is parsed.
Parsing the hostname and process¶
Next, parse the hostname and process: asgmtx sshd[17112]:.
Remember, the first log's header is different than the rest. For a solution that accommodates this difference, create a parser declaration and a subparser declaration.
As seen in the first parser declaration:
# Hostname and process
- HOSTNAME: !PARSE.UNTIL ' ' # asgmtx
- PROCESS: !PARSE.UNTIL ':'
# Message
- !PARSE.SPACES
- MESSAGE: !PARSE.CHARS
- Parse the hostname: To parse the hostname, use the
!PARSE.UNTILexpression to parse everything until the single character specified inside' ', which in this case is a space, and stops after that character, without including the character in the output. - Parse the process: Use
!PARSE.UNTILagain for parsing until:. After the colon ('), the header is parsed. - Parse the message: In this declaration, use
!PARSE.SPACESto parse all spaces between the header and the message. Then, store the rest of the event in theMESSAGEfield using the!PARSE.CHARSexpression, which in this case parses all of the rest of the characters in the log. You will use additional declarations to parse the parts of the message.
1.5. Parsing for log variance¶
To address the issue of the first log not having a process PID, you need a second parser declaration, a subparser. In the other logs, the process PID is enclosed in square brackets ([ ]).
Create a declaration called 15_parser_process.yaml. To accommodate the differences in the logs, create two "paths" or "branches" that the parser can use. The first branch will parse PROCESS.NAME, PROCESS.PID and :. The second branch will parse only PROCESS.NAME.
Why do I need two branches?
For three of the logs, the process PID is enclosed in square brackets ([ ]). Thus, the expression that isolates the PID begins parsing at a square bracket [. However, in the first log, the PID field is not present. If you try to parse the first log using the same expression, the parser will try to find a square bracket in that log and will keep searching regardless of the character [ not being present in the header.
The result would be that whatever is inside the square brackets is parsed as PID, which in this case would be nonsensical, and would disrupt the rest of the parsing process for that log.


The second declaration:
---
define:
type: parser/parsec
field: PROCESS
error: continue
parse:
!PARSE.KVLIST
- !TRY
- !PARSE.KVLIST
- PROCESS.NAME: !PARSE.UNTIL '['
- PROCESS.PID: !PARSE.UNTIL ']'
- !PARSE.KVLIST
- PROCESS.NAME: !PARSE.CHARS
To achieve this, construct two little parsers under the combinator !PARSE.KVLIST using the !TRY expression.
The !TRY expression
The !TRY expression allows you to nest a list of expressions under it. !TRY begins by attempting to use the first expression, and if that first expression is unusable for the log, the process continues with the second nested expression, and so on, until an expression succeeds.
Under the !TRY expression:
The first branch:
1. The expression parses PROCESS.NAME and PROCESS.PID, expecting the square brackets [ and ] to be present in the event. After these are parsed, it also parses the : character.
2. If the log does not contain a [ character, the expression !PARSE.UNTIL '[' fails, and in that case the whole !PARSE.KVLIST expression in the first branch fails.
The second branch:
3. The !TRY expression will continue with the next parser, which does not require the character [ to be present in the event. It simply parses everything before : and stops after it.
4. If this second expression fails, the log goes to OTHERS.
2. Parsing the message¶
Consider again the events:
<181>2023:01:12-13:08:45 asgmtx httpd: 212.158.149.81 - - [12/Jan/2023:13:08:45 +0100] "POST /webadmin.plx HTTP/1.1" 200 2000
<38>2023:01:12-13:09:09 asgmtx sshd[17112]: Failed password for root from 218.92.0.190 port 56745 ssh2
<38>2023:01:12-13:09:20 asgmtx sshd[16281]: Did not receive identification string from 218.92.0.190
<38>2023:01:12-13:09:20 asgmtx aua[2350]: id="3005" severity="warn" sys="System" sub="auth" name="Authentication failed" srcip="43.139.111.88" host="" user="login" caller="sshd" reason="DENIED"
There are three different types of messages, dependent on the process name.
httpd: Message is in a structured format. We can extract the data such as IPs and HTTP requests easily by using the standard parsing expressions.sshd: Message is a human-readable string. To extract the data such as host IPs and ports, hardcode these messages in the parser and skip the words that are relevant to humans but not relevant for automatic parsing.aua: Message consists of structured data in the form of key-value pairs. Extract them as they are and rename them in the mapping according to the Elasticsearch Common Schema.
For clarity, put each declaration into a separate YAML file and use the !INCLUDE expression for including them into one parser.
---
define:
type: parser/parsec
field: MESSAGE
error: continue
parse:
!MATCH
what: !GET { from: !ARG EVENT, what: process.name, type: str }
with:
'httpd': !INCLUDE httpd.yaml
'sshd': !INCLUDE sshd.yaml
'aua': !INCLUDE aua.yaml
else: !PARSE.KVLIST []
The !MATCH expression has three parameters. The what parameter specifies the field name, the value is matched with one of the cases specified in with dictionary. If match is successful, the corresponding expression will be executed, in this case one of !INCLUDE expressions. If none of the listed cases matches, the expression in else is executed. In this case, !PARSE.KVLIST is used with an empty list, which means nothing will be parsed from the message.
Parsing the structured message¶
First, look at the message from 'httpd' process.
212.158.149.81 - - [12/Jan/2023:13:08:45 +0100] "POST /webadmin.plx HTTP/1.1" 200 2000
Parse the IP address, the HTTP request method, the response status and the number of bytes requested to yield the output:
host.ip: '212.158.149.81'
http.request.method: 'POST'
http.response.status_code: '200'
http.response.body.bytes: '2000'
This is straightforward, assuming all the events will satisfy the same format as the one from the example:
!PARSE.KVLIST
- host.ip: !PARSE.UNTIL ' '
- !PARSE.UNTIL '"'
- http.request.method: !PARSE.UNTIL ' '
- !PARSE.UNTIL '"'
- !PARSE.SPACE
- http.response.status_code: !PARSE.DIGITS
- !PARSE.SPACE
- http.request.body.bytes: !PARSE.DIGITS
This case uses the ECS for naming. Alternatively, you can rename fields according to your needs in the mapping declaration.
Parsing the human-readable string¶
Let us continue with 'sshd' messages.
Failed password for root from 218.92.0.190 port 56745 ssh2
Did not receive identification string from 218.92.0.190
You can extract IP addresses from both events and the port from the first one. Additionally, you can store the condensed information about the event type in event.action field.
event.action: 'password-failed'
user.name: 'root'
source.ip: '218.92.0.190'
source.port: '56745'
event.action: 'id-string-not-received'
source.ip: '218.92.0.190'
To differentiate between these two messages, notice that each of them starts with a different prefix. You can take advantage of this and use !PARSE.TRIE expression.
!PARSE.TRIE
- 'Failed password for ': !PARSE.KVLIST
- event.action: 'password-failed'
- user.name: !PARSE.UNTIL ' '
- 'from '
- source.ip: !PARSE.UNTIL ' '
- 'port '
- source.port: !PARSE.DIGITS
- 'Did not receive identification string from ': !PARSE.KVLIST
- event.action: 'id-string-not-received'
- source.ip: !PARSE.CHARS
- '': !PARSE.KVLIST []
!PARSE.TRIE expression tries to match the incoming string with the listed prefixes and performs the corresponding expressions. The empty prefix '' is a fallback: if none of the listed prefixes match, the empty one is used.
Parsing key-value pairs¶
Finally, aua events have key-value pairs.
id="3005" severity="warn" sys="System" sub="auth" name="Authentication failed" srcip="43.139.111.88" host="" user="login" caller="sshd" reason="DENIED"
Desired output:
id: '3005'
severity: 'warn'
sys: 'System'
sub: 'auth'
name: 'Authentication failed'
srcip: '43.139.111.88'
host: ''
user: 'login'
caller: 'sshd'
reason: 'DENIED'
When encountering structured messages, you can use !PARSE.REPEAT together with !PARSE.KV.
The !PARSE.REPEAT expression performs the expression specified in what parameter multiple times. In this case, you want to repeat the steps until it is no longer possible:
- Parse everything until '=' character and use it as a key.
- Parse everything between '"' characters and assign that value to the key.
- Optionally, omit spaces before the next key begins.
For that, we create the following expression:
!PARSE.KVLIST
- !PARSE.REPEAT
what: !PARSE.KV
- !PARSE.OPTIONAL { what: !PARSE.SPACE }
- key: !PARSE.UNTIL '='
- value: !PARSE.BETWEEN '"'
KV in !PARSE.KV stands for key-value. This expression takes a list of parsing expressions, including the keywords key and value.
3. Mapping declaration¶
Mapping renames the keys so that they correspond to the ECS (Elastic Common Schema).
---
define:
type: parser/mapping
schema: /Schemas/ECS.yaml
mapping:
# 10_parser_header.yaml and 15_parser_process.yaml
'PRI': 'log.syslog.priority'
'TIMESTAMP': '@timestamp'
'HOSTNAME': 'host.hostname'
'PROCESS.NAME': 'process.name'
'PROCESS.PID': 'process.pid'
'MESSAGE': 'message'
# 20_parser_message.yaml
# httpd.yaml
- 'host.ip': 'host.ip'
- 'http.request.method': 'http.request.method'
- 'http.response.status_code': 'http.response.status_code'
- 'http.request.body.bytes': 'http.request.body.bytes'
# sshd.yaml
'event.action': 'event.action'
'user.name': 'user.name'
'source.ip': 'source.ip'
'source.port': 'source.port'
# aua.yaml
'sys': 'sophos.sys'
'host': 'sophos.host'
'user': 'sophos.user'
'caller': 'log.syslog.appname'
'reason': 'event.reason'
Mapping as a filter
Note that we must map fields from httpd.yaml and sshd.yaml files, although they are already in ECS format. The mapping processor also work as a filter. Any key you do not include in the mapping declaration is dropped from the event. This is the case of aua.yaml, where some fields are not included in mapping and therefore skipped.
4. Enricher declaration¶
The enricher will have this structure:
---
define:
type: parsec/enricher
enrich:
...
For the purpose of this example, the enricher will
- Add the fields
event.datasetanddevice.model.identifier, which will be "static" fields, always with the same value. - Transform the field
HOST.HOSTNAMEto lowercase,host.hostname. - Compute the syslog facility and severity from syslog priority, both with numeric and readable value.
Note that enrichers do not modify or delete the already existing fields, unless you explicitly specify it in the declaration. This is done by creating a field that is already existing in the event. In that case, the field is simply replaced by the new value.
Enriching simple fields¶
To enrich the event with event.dataset supplemented by device.model.identifier:
event.dataset: "sophos"
device.model.identifier: "SG230"
For that, specify these fields in the enricher, and the fields will be added to the event every time.
---
define:
type: parsec/enricher
enrich:
event.dataset: "sophos"
device.model.identifier: "SG230"
Editing existing fields¶
You can perform some operations with already existing fields. In this case, the goal is to change HOST.HOSTNAME to lowercase, host.hostname. For that, use the following expression:
host.hostname: !LOWER
what: !GET {from: !ARG EVENT, what: host.hostname}
You can also change the field name. If you do it like this,
host.id: !LOWER
what: !GET {from: !ARG EVENT, what: host.hostname}
the output would include the original field host.hostname as well as a new lowercase field host.id.
Computing facility and severity from priority¶
Syslog severity and facility are computed from syslog priority by the formula:
PRIORITY = FACILITY * 8 + SEVERITY
There is a shortcut for faster computation that uses the fact that numbers are represented in binary format.
The shortcut allows the use of low level operations such as !SHR (right shift) and !AND.
8 = 2^3, therefore obtaining an integer quotient after dividing by 8 is done by performing the right shift by 3.
Integer 7 in binary representation is 111, therefore applying !AND operation gives the remainder after dividing by 8.
The expression is the following:
log.syslog.facility.code: !SHR { what: !GET { from: !ARG EVENT, what: log.syslog.priority }, by: 3 }
log.syslog.severity.code: !AND [ !GET { from: !ARG EVENT, what: log.syslog.priority }, 7 ]
You can consider the number 38 to illustrate this concept. 38 is 100 110 in binary representation. Dividing it by 8 is the same as right shift by 3 places, which is 11 in binary representation.
shr(100 110, 11) = 000 100
which is 4. So the value of FACILITY is 4, which corresponds to AUTH. Performing !AND operation gives
and(100 100, 111) = 000 100
which is again 4. So the value of SEVERITY is 4, which corresponds to WARNING.
You can also match the numeric values of severity and facility with human-readable names using the !MATCH expression. The complete declaration is the following:
---
define:
type: parsec/enricher
enrich:
# New fields
event.dataset: "sophos"
device.model.identifier: "SG230"
# Lowercasing the existing field
host.hostname: !LOWER
what: !GET {from: !ARG EVENT, what: host.hostname}
# SYSLOG FACILITY
log.syslog.facility.code: !SHR { what: !GET { from: !ARG EVENT, what: log.syslog.priority }, by: 3 }
log.syslog.facility.name: !MATCH
what: !GET { from: !ARG EVENT, what: log.syslog.facility.code }
with:
0: 'kern'
1: 'user'
2: 'mail'
3: 'daemon'
4: 'auth'
5: 'syslog'
6: 'lpr'
7: 'news'
8: 'uucp'
9: 'cron'
10: 'authpriv'
11: 'ftp'
16: 'local0'
17: 'local1'
18: 'local2'
19: 'local3'
20: 'local4'
21: 'local5'
22: 'local6'
23: 'local7'
# SYSLOG SEVERITY
log.syslog.severity.code: !AND [ !GET { from: !ARG EVENT, what: log.syslog.priority }, 7 ]
log.syslog.severity.name: !MATCH
what: !GET { from: !ARG EVENT, what: log.syslog.severity.code }
with:
0: 'emergency'
1: 'alert'
2: 'critical'
3: 'error'
4: 'warning'
5: 'notice'
6: 'information'
7: 'debug'