Connecting a new log source to LogMan.io¶
Prerequisites¶
Tenant¶
Each customer is assigned one or more tenants.
Name of the tenant must be a lowercase ASCII name, that tag the data/logs belonging to the user and store each tenant's data in a separate ElasticSearch index. All Event Lanes (see below) are also tenant specific.
Create the tenant in SeaCat Auth using LogMan.io UI¶
In order to create the tenant, log into the LogMan.io UI with the superuser role, which can be done through the provisioning. For more information about provisioning, please refer to Provisioning mode section of the SeaCat Auth documentation.
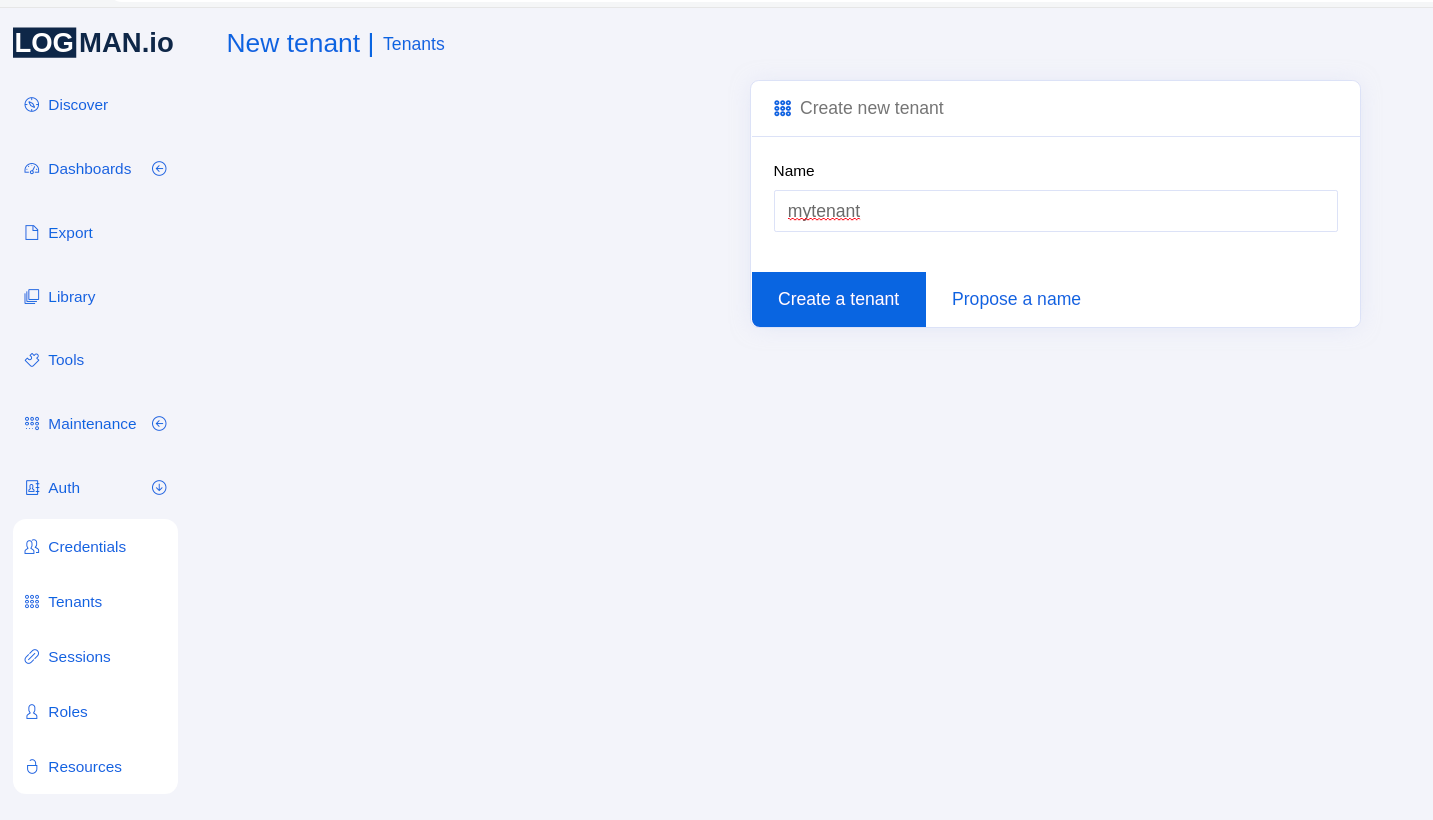
In LogMan.io UI, navigate to the Auth section in the left menu and select Tenants.
Once there, click on Create tenant option and write the name of the tenant there.
Then click on the blue button and the tenant should be created:
After that, go to Credentials and assign the newly created tenant to all relevant users.
ElasticSearch index templates¶
In Kibana, every tenant should have index templates for lmio-tenant-events and lmio-tenant-others indices, where tenant is the name of the tenant (refer to the reference site- repository provided by TeskaLabs), so proper data types are assigned to every field.
This is especially needed for time-based fields, which would not work without index template and could not be used for sorting and creating index patterns in Kibana.
The ElasticSearch index template should be present in the site- repository
under the name es_index_template.json.
The index templates can be inserted via Kibaba's Dev Tools from the left menu.
ElasticSearch index lifecycle policy¶
Index Lifecycle Management (ILM) in ElasticSearch serves to automatically close or delete old indices (f. e. with data older than three months), so searching performance is kept and data storage is able to store present data. The setting is present in the so-called ILM policy.
The ILM should be set before the data are pumped into ElasticSearch, so the new index finds and associates itself with the proper ILM policy. For more information, please refer to the official documentation: https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started-index-lifecycle-management.html
LogMan.io components such as Dispatcher then use a specified ILM alias (lmio-) and ElasticSearch automatically put the data to the proper index assigned with the ILM policy.
The setting should be done in following way:
Create the ILM policy¶
Kibana version 7.x can be used to create ILM policy in ElasticSearch.
1.) Open Kibana
2.) Click Management in the left menu
3.) In the ElasticSearch section, click on Index Lifecycle Policies
4.) Click Create policy blue button
5.) Enter its name, which should be the same as the index prefix, f. e. lmio-
6.) Set max index size to the desired rollover size, f. e. 25 GB (size rollover)
7.) Set maximum age of the index, f. e. 10 days (time rollover)
8.) Click the switch down the screen at Delete phase, and enter the time after which the index should be deleted, f. e. 120 days from rollover
9.) Click on Save policy green button
Use the policy in index template¶
Add the following lines to the JSON index template:
"settings": {
"index": {
"lifecycle": {
"name": "lmio-",
"rollover_alias": "lmio-"
}
}
},
ElasticSearch indices¶
Through PostMan or Kibana, create a following HTTP request to the instance of ElasticSearch you are using.
1.) Create a index for parsed events/logs:
PUT lmio-tenant-events-000001
{
"aliases": {
"lmio-tenant-events": {
"is_write_index": true
}
}
}
2.) Create a index for unparsed and error events/logs:
PUT lmio-tenant-others-000001
{
"aliases": {
"lmio-tenant-others": {
"is_write_index": true
}
}
}
The alias is then going to be used by the ILM policy to distribute data to the proper ElasticSearch index, so pumps do not have to care about the number of the index.
//Note: The prefix and number of index for ILM rollover must be separated with -000001, not _000001!//
Event Lane¶
Event Lane in LogMan.io define how logs from a specific data source for a given tenant are sent to the cluster. Each event lane is specific for the collected source. Each event lane consists of one lmio-collector service, one lmio-ingestor service and one or more instances of lmio-parser service.
Collector¶
LogMan.io Collector should run on the collector server or on one or more LogMan.io servers, if they are part of the same internal network. The configuration sample is part of the reference site- repository.
LogMan.io Collector is able to, via YAML configuration, open a TCP/UDP port to obtain logs from, read files, open a WEC server, read from Kafka topics, Azure accounts and so on. The comprehensive documentation is available here: LogMan.io Collector
The following configuration sample opens 12009/UDP port on the server the collector is installed to, and redirects the collected data via WebSocket to the lm11 server to port 8600, where lmio-ingestor should be running:
input:Datagram:UDPInput:
address: 0.0.0.0:12009
output: WebSocketOutput
output:WebSocket:WebSocketOutput:
url: http://lm11:8600/ws
tenant: mytenant
debug: false
prepend_meta: false
The url is either the hostname of the server and port of the Ingestor, if Collector and Ingestor are deployed to the same server, or URL with https://, if collector server outside of the internal network is used. It is then necessary to specify HTTPS certificates, please see the output:WebSocket section in the LogMan.io Collector Outputs guide for more information.
The tenant is the name of the tenant the logs belong to. The tenant name is then automatically propagated to Ingestor and Parser.
Ingestor¶
LogMan.io Ingestor takes the log messages from Collector along with metadata and stores them in Kafka in a topic, that begins with collected-tenant- prefix, where tenant is the tenant name the logs belong to and technology the name of the technology the data are gathered from like microsoft-windows.
The following sections in the CONF files are necessary to be always set up differently for each event lane:
# Output
[pipeline:WSPipeline:KafkaSink]
topic=collected-tenant-technology
# Web API
[web]
listen=0.0.0.0 8600
The port in the listen section should match the port in the Collector YAML configuration (if the Collector is deployed to the same server) or the setting in nginx (if the data are collected from a collector server outside of the internal network). Please refer to the reference site- repository provided by TeskaLabs' developers.
Parser¶
The parser should be deployed in more instances to scale the performance. It parses the data from original bytes or strings to a dictionary in the specified schema like ECS (ElasticSearch Schema) or CEF (Common Event Format), while using a parsing group from the library loaded in ZooKeeper. It is important to specify the Kafka topic to read from, which is the same topic as specified in the Ingestor configuration:
[declarations]
library=zk://lm11:2181/lmio/library.lib
groups=Parsers/parsing-group
raw_event=log.original
# Pipeline
[pipeline:ParsersPipeline:KafkaSource]
topic=collected-tenant-technology
group_id=lmio_parser_collected
auto.offset.reset=smallest
Parsers/parsing-group is the location of the parsing group from the library loaded in ZooKeeper through LogMan.io Commander. It does not have to exist at the first try, because all data are then automatically send to lmio-tenant-others index. When the parsing group is ready, the parsing takes place and the data can be seen in the document format in lmio-tenant-events index.
Kafka topics¶
Before all three services are started via docker-compose up -d command, it is important to check the state of the specific collected-tenant-technology Kafka topic (where tenant is the name of the tenant and technology is the name of the connected technology/device type). In the Kafka container (f. e.: docker exec -it lm11_kafka_1 bash), the following commands should be run:
/usr/bin/kafka-topics --zookeeper lm11:2181 --create --topic collected-tenant-technology --replication-factor 1 --partitions 6
/usr/bin/kafka-topics --zookeeper lm11:2181 --alter --topic collected-tenant-technology --config retention.ms=86400000
Parsing groups¶
For most common technologies, TeskaLabs have already prepared the parsing groups to ECS schema. Please get in touch with TeskaLabs developers. Since all parsers are written in the declarative language, all parsing groups in the library can be easily adjusted. The name of the group should be the same as the name of the dataset attribute written in the parser groups' declaration.
For more information about our declarative language, please refer to the official documentation: SP-Lang
After the parsing group is deployed via LogMan.io Commander, the appropriate Parser(s) should be restarted.
Deployment¶
On the LogMan.io servers, simply run the following command in the folder the site- repository is cloned to:
docker-compose up -d
The collection of logs can be then checked in the Kafka Docker container via Kafka's console consumer:
/usr/bin/kafka-console-consumer --bootstrap-server lm11:9092 --topic collected-tenant-technology --from-beginning
The data are pumped in Parser from collected-tenant-technology topic to lmio-events or lmio-others topic and then in Dispatcher (lmio-dispatcher) to lmio-tenant-events or lmio-tenant-others index in ElasticSearch.