Připojení nového zdroje logů k LogMan.io¶
Předpoklady¶
Tenant¶
Každý zákazník má přiřazeno jednoho nebo více tenantů.
Název tenantu musí být malými písmeny v ASCII formátu, který označuje data/logy náležející uživateli a ukládá data každého tenantu do samostatného indexu v ElasticSearch. Všechny Event Lanes (viz níže) jsou také specifické pro tenanty.
Vytvoření tenantu v SeaCat Auth pomocí LogMan.io UI¶
Pro vytvoření tenantu se přihlaste do LogMan.io UI s rolí superuživatele, což lze provést prostřednictvím provisioning. Pro více informací o provizionování prosím odkázat na sekci Provisioning mode v dokumentaci SeaCat Auth.
V LogMan.io UI přejděte do sekce Auth v levém menu a vyberte Tenants. Jakmile tam budete, klikněte na možnost Create tenant a zadejte název tenantu. Poté klikněte na modré tlačítko a tenant by měl být vytvořen:
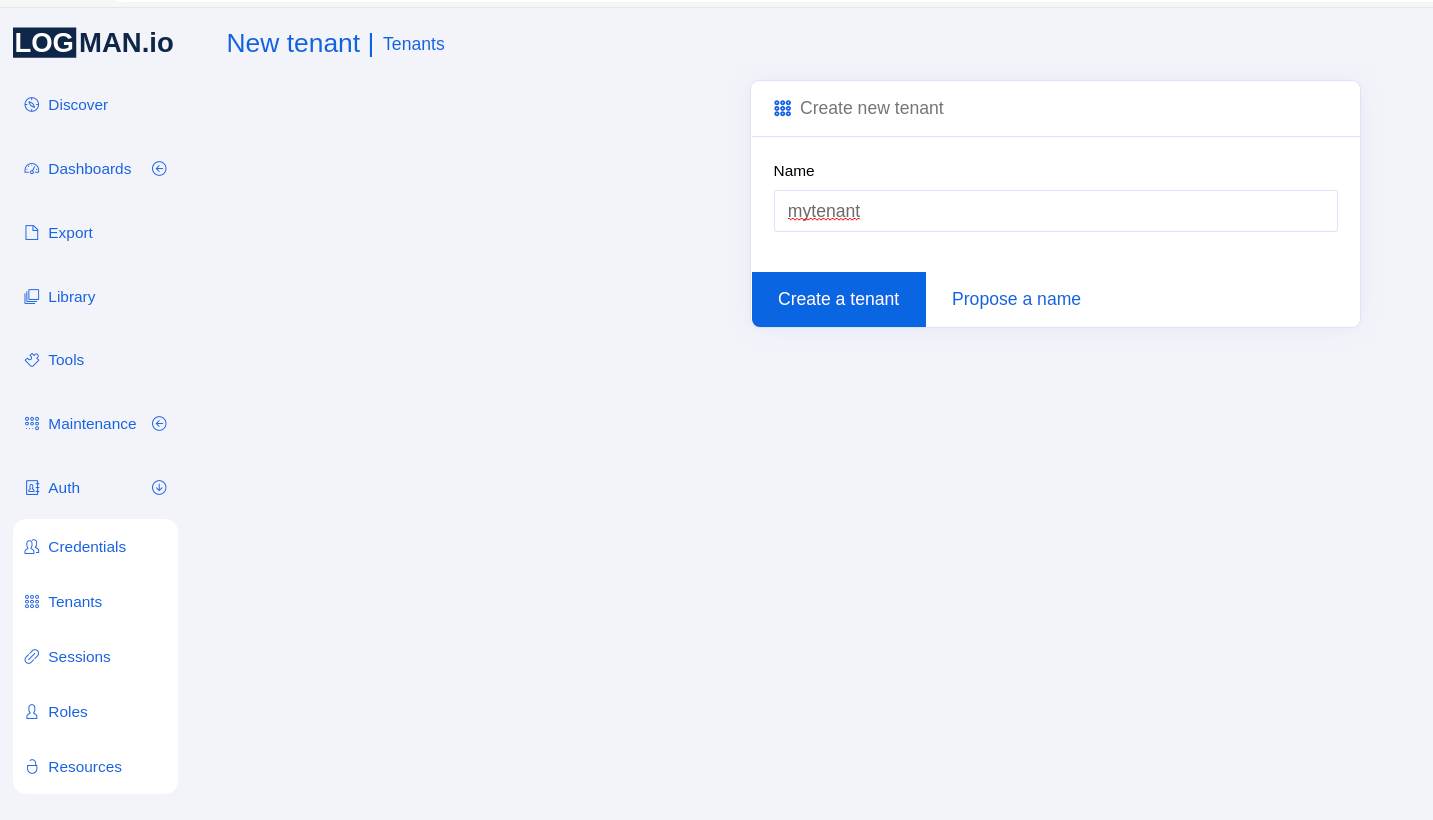
Poté přejděte do Credentials a přiřaďte nově vytvořený tenant všem relevantním uživatelům.
Šablony indexů v ElasticSearch¶
V Kibana by měl mít každý tenant šablony indexů pro indexy lmio-tenant-events a lmio-tenant-others, kde tenant je název tenantu (odkazujte na referenční site- repo poskytované TeskaLabs), takže každému poli jsou přiřazeny správné datové typy.
To je zvláště nutné pro časově založená pole, která by nefungovala bez šablony indexu a nemohla by být použita pro třídění a vytváření šablon indexů v Kibana.
Šablona indexu ElasticSearch by měla být přítomna v site- repo pod názvem es_index_template.json.
Šablony indexů lze vložit pomocí Dev Tools v Kibaba z levého menu.
Politika životního cyklu indexů v ElasticSearch¶
Index Lifecycle Management (ILM) v ElasticSearch slouží k automatickému uzavření nebo smazání starých indexů (např. s daty staršími než tři měsíce), takže performance hledání je zachována a úložiště dat je schopné ukládat aktuální data. Nastavení je přítomno v tzv. ILM politice.
ILM by měla být nastavena předtím, než jsou data napumpována do ElasticSearch, takže nový index najde a přiřadí se správné ILM politice. Pro více informací prosím odkázat na oficiální dokumentaci: https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started-index-lifecycle-management.html
Komponenty LogMan.io jako Dispatcher pak používají specifikální ILM alias (lmio-) a ElasticSearch automaticky přiřadí data do správného indexu přiřazeného k ILM politice.
Nastavení by mělo být provedeno následujícím způsobem:
Vytvoření ILM politiky¶
Pro vytvoření ILM politiky v ElasticSearch lze použít Kibana verze 7.x.
1.) Otevřete Kibana
2.) Klikněte na Management v levém menu
3.) V sekci ElasticSearch klikněte na Index Lifecycle Policies
4.) Klikněte na tlačítko Create policy
5.) Zadejte jeho název, který by měl být stejný jako předpona indexu, např. lmio-
6.) Nastavte max velikost indexu na požadovanou velikost pro otočení, např. 25 GB (velikost pro otočení)
7.) Nastavte maximální věk indexu, např. 10 dní (čas pro otočení)
8.) Klikněte na přepínač na dolní obrazovce u fáze Delete a zadejte čas po kterém má být index smazán, např. 120 dní od otočení
9.) Klikněte na tlačítko Save policy
Použití politiky v šabloně indexu¶
Přidejte následující řádky do JSON šablony indexu:
"settings": {
"index": {
"lifecycle": {
"name": "lmio-",
"rollover_alias": "lmio-"
}
}
},
Indexy v ElasticSearch¶
Prostřednictvím PostMan nebo Kibana, vytvořte následující HTTP requesty na instanci ElasticSearch, kterou používáte.
1.) Vytvořte index pro parsované události/logy:
PUT lmio-tenant-events-000001
{
"aliases": {
"lmio-tenant-events": {
"is_write_index": true
}
}
}
2.) Vytvořte index pro neparsované a chybové události/logy:
PUT lmio-tenant-others-000001
{
"aliases": {
"lmio-tenant-others": {
"is_write_index": true
}
}
}
Alias je pak použit ILM politikou pro distribuci dat do správného indexu ElasticSearch, takže pumpy se nemusí starat o počet indexů.
//Poznámka: Předpona a číslo indexu pro ILM rollover musí být odděleny pomocí -000001, nikoliv _000001!//
Event Lane¶
Event Lane v LogMan.io definuje, jak jsou logy z konkrétního zdroje dat pro dodaného tenanta odesílány do clusteru. Každá event lane je specifická pro sesbíraný zdroj. Každá event lane se skládá z jedné lmio-collector služby, jedné lmio-ingestor služby a jednoho nebo více instancí lmio-parser služby.
Collector¶
LogMan.io Collector by měl běžet na collector serveru nebo na jednom nebo více serverech LogMan.io, pokud jsou součástí stejné interní sítě. Ukázka konfigurace je součástí referenčního site- repo.
LogMan.io Collector je schopný prostřednictvím YAML konfigurace otevřít TCP/UDP port pro získávání logů, číst soubory, otevřít WEC server, číst z Kafka témat, Azure účtů atd. Komplexní dokumentace je dostupná zde: LogMan.io Collector
Následující ukázka konfigurace otevírá 12009/UDP port na serveru, kde je collector nainstalován, a přesměrovává sesbíraná data přes WebSocket na server lm11 na port 8600, kde by měl běžet lmio-ingestor:
input:Datagram:UDPInput:
address: 0.0.0.0:12009
output: WebSocketOutput
output:WebSocket:WebSocketOutput:
url: http://lm11:8600/ws
tenant: mytenant
debug: false
prepend_meta: false
url je buď hostname serveru a port Ingestoru, pokud jsou Collector a Ingestor nasazeny na stejném serveru, nebo URL s https://, pokud je použit collector server mimo interní síť. Poté je nutné specifikovat HTTPS certifikáty, prosím viz sekci output:WebSocket v LogMan.io Collector Outputs průvodce pro více informací.
tenant je název tenantu, k němuž patří logy. Název tenantu je pak automaticky propagován k Ingestoru a Parseru.
Ingestor¶
LogMan.io Ingestor přijímá log zprávy od Collectoru spolu s metadaty a ukládá je do Kafka do tématu, které začíná předponou collected-tenant-, kde tenant je název tenantu, ke kterému logy patří a technology je název technologie, z které data pocházejí jako například microsoft-windows.
Následující sekce v souborech CONF by vždy měly být nastavovány rozdílně pro každou event lane:
# Výstup
[pipeline:WSPipeline:KafkaSink]
topic=collected-tenant-technology
# Web API
[web]
listen=0.0.0.0 8600
Port v sekci listen by měl odpovídat portu v YAML konfiguraci Collectoru (pokud je Collector nasazen na stejném serveru) nebo nastavení v nginx (pokud jsou data sbírána z collector serveru mimo interní síť). Prosím, odkazujte na referenční site- repo poskytované vývojáři TeskaLabs.
Parser¶
Parser by měl být nasazen ve více instancích pro škálování výkonu. Parsuje data z původních bajtů nebo řetězců do slovníku ve specifikovaném schématu jako ECS (ElasticSearch Schema) nebo CEF (Common Event Format), přičemž používá parserovou skupinu z knihovny načtené v ZooKeeper. Je důležité specifikovat Kafka téma, ze kterého číst, což je stejné téma jako uvedeno v konfiguraci Ingestoru:
[declarations]
library=zk://lm11:2181/lmio/library.lib
groups=Parsers/parsing-group
raw_event=log.original
# Pipeline
[pipeline:ParsersPipeline:KafkaSource]
topic=collected-tenant-technology
group_id=lmio_parser_collected
auto.offset.reset=smallest
Parsers/parsing-group je umístění parsingové skupiny z knihovny načtené v ZooKeeper prostřednictvím LogMan.io Commander. Nemusí existovat na první pokus, protože všechna data pak jsou automaticky odeslána do lmio-tenant-others indexu. Když je parsingová skupina připravena, parsing proběhne a data mohou být viděna v dokumentovém formátu v lmio-tenant-events indexu.
Kafka témata¶
Než jsou všechny tři služby spuštěny příkazem docker-compose up -d, je důležité zkontrolovat stav specifického Kafka tématu collected-tenant-technology (kde tenant je název tenantu a technology je název připojené technologie/typu zařízení). V kontejneru Kafka (např.: docker exec -it lm11_kafka_1 bash), by měly být spuštěny následující příkazy:
/usr/bin/kafka-topics --zookeeper lm11:2181 --create --topic collected-tenant-technology --replication-factor 1 --partitions 6
/usr/bin/kafka-topics --zookeeper lm11:2181 --alter --topic collected-tenant-technology --config retention.ms=86400000
Parsingové skupiny¶
Pro nejběžnější technologie již TeskaLabs připravila parsingové skupiny do ECS schématu. Prosím, spojte se s vývojáři TeskaLabs. Vzhledem k tomu, že všechny parsers jsou napsány v deklarativním jazyce, všechny parsingové skupiny v knihovně mohou být snadno upraveny. Název skupiny by měl být stejný jako název atributu dataset napsaný v deklaraci parse skupin.
Pro více informací o našem deklarativním jazyce prosím odkazujte na oficiální dokumentaci: SP-Lang
Po nasazení parsingové skupiny prostřednictvím LogMan.io Commander, by měl být restartován příslušný Parser(y).
Nasazení¶
Na serverech LogMan.io jednoduše spusťte následující příkaz ve složce, kde je naklonované site- repo:
docker-compose up -d
Sběr logů lze poté zkontrolovat v Docker kontejneru Kafka prostřednictvím Kafka konzolového konzumenta:
/usr/bin/kafka-console-consumer --bootstrap-server lm11:9092 --topic collected-tenant-technology --from-beginning
Data jsou nasávána Parserem z témata collected-tenant-technology do témat lmio-events nebo lmio-others a poté v Dispatcher (lmio-dispatcher) do indexů lmio-tenant-events nebo lmio-tenant-others v ElasticSearch.