Průvodce nasazením TeskaLabs LogMan.io pro partnery
Předimplementační analýza
Každé dodání by mělo začít předimplementační analýzou, která uvádí všechny zdroje logů, které by měly být připojeny k LogMan.io. Výstupem analýzy je tabulka, kde každý řádek popisuje jeden zdroj logů, způsob získávání logů (čtení souborů, přesměrování logů na cílový port atd.), kdo je odpovědný za zdroj logů z pohledu zákazníka a odhad, kdy by měl být zdroj logů připojen. Viz následující obrázek:

Na obrázku jsou dva další sloupce, které nejsou součástí předimplementační analýzy a jsou doplněny později během realizace (kafka topic a dataset). Pro více informací viz sekce Event lanes níže.
MUSÍ BÝT definováno, která doména (URL) bude použita k hostování LogMan.io.
Zákazník nebo partner sám by měl poskytnout vhodné HTTPS SSL certifikáty (viz nginx níže), například pomocí Let's Encrypt nebo jiné certifikační autority.
LogMan.io cluster a sběračské servery
Servery
Na konci předimplementační analýzy by mělo být jasné, jak velký objem shromážděných logů (v událostech nebo zprávách za sekundu, zkráceně EPS) by měl být. Logy jsou vždy shromažďovány z infrastruktury zákazníka alespoň jedním serverem vyhrazeným pro sběr logů (takzvaný log collector).
Pokud jde o LogMan.io cluster, existují tři způsoby:
- LogMan.io cluster je nasazen v infrastruktuře zákazníka na fyzických nebo virtuálních strojích (on-premise)
- LogMan.io cluster je nasazen v infrastruktuře partnera a je dostupný pro více zákazníků, kde každý zákazník má přiděleného jednoho
tenanta (SoC, SaaS atd.)
Viz sekci Specifikace hardwaru pro více informací o konfiguraci fyzických serverů.
Architektura clusteru
V kterémkoliv způsobu nasazení clusteru by měl být k dispozici alespoň jeden server (pro PoC) nebo alespoň tři servery (pro nasazení) pro LogMan.io cluster. Pokud je cluster nasazen v infrastruktuře zákazníka, servery mohou rovněž fungovat jako sběračské servery, takže v tomto případě není třeba mít vyhrazený sběračský server. Architektura tří serverů může sestávat ze tří podobných fyzických serverů nebo dvou fyzických serverů a jednoho malého libovolného virtuálního stroje.
Menší nebo nekritická nasazení jsou možná na konfiguracích s jedním serverem.
Pro více informací o organizaci LogMan.io clusteru viz sekci Architektura clusteru.
Datové úložiště
Každý fyzický nebo ne-arbitrární server v LogMan.io clusteru by měl mít dostatek dostupného diskového úložiště, aby mohl uchovávat data po požadovanou dobu z předimplementační analýzy.
Mělo by být k dispozici alespoň jedno rychlé (pro aktuální nebo jednodenní logy a Kafka topics) a jedno pomalejší (pro starší data, metadata a konfigurace) datové úložiště připojené k /data/ssd a /data/hdd.
Protože všechny LogMan.io služby běží jako Docker kontejnery, složka /var/lib/docker by měla být rovněž připojena k jednomu z těchto úložišť.
Pro podrobnější informace o organizaci diskového úložiště, montáži atd. navštivte sekci Datové úložiště.
Instalace
DOPORUČENÝ operační systém je Linux Ubuntu 22.04 LTS nebo novější. Alternativy jsou Linux RedHat 8 a 7, CentOS 7.
Názvy hostitelů LogMan.io serverů v LogMan.io clusteru by měly dodržovat notaci lm01, lm11 atd.
Pokud jsou použity oddělené sběračské servery (viz výše), není pro jejich názvy hostitelů žádné omezení.
Pokud je součástí dodávky TeskaLabs, měl by být vytvořen uživatel tladmin s povoleními sudoer.
Na každém serveru (jak LogMan.io clusteru, tak Collector), by měly být nainstalovány git, docker a docker-compose.
Odkazujte na Manuální instalaci pro komplexní průvodce.
Všechny služby jsou pak vytvořeny a spuštěny pomocí příkazu docker-compose up -d z adresáře, do kterého je naklonováno repozitář site (viz následující sekce):
$ cd /opt/site-tenant-siterepository/lm11
$ docker-compose up -d
Přístupové údaje k Dockeru jsou partnerovi poskytovány týmem TeskaLabs.
Site repozitář a konfigurace
Každý partner má přístup k TeskaLabs GitLab, kde spravuje konfigurace pro nasazení, což je doporučený způsob, jak uložit konfigurace pro budoucí konzultace s TeskaLabs. Nicméně každý partner může také použít svůj vlastní GitLab nebo jakýkoli jiný Git repozitář a poskytnout týmu TeskaLabs vhodné (alespoň čtecí) přístupy.
Každé nasazení pro každého zákazníka by mělo mít samostatný site repozitář, bez ohledu na to, zda je instalován celý LogMan.io cluster nebo jen sběračské servery. Struktura site repozitáře by měla vypadat následovně:
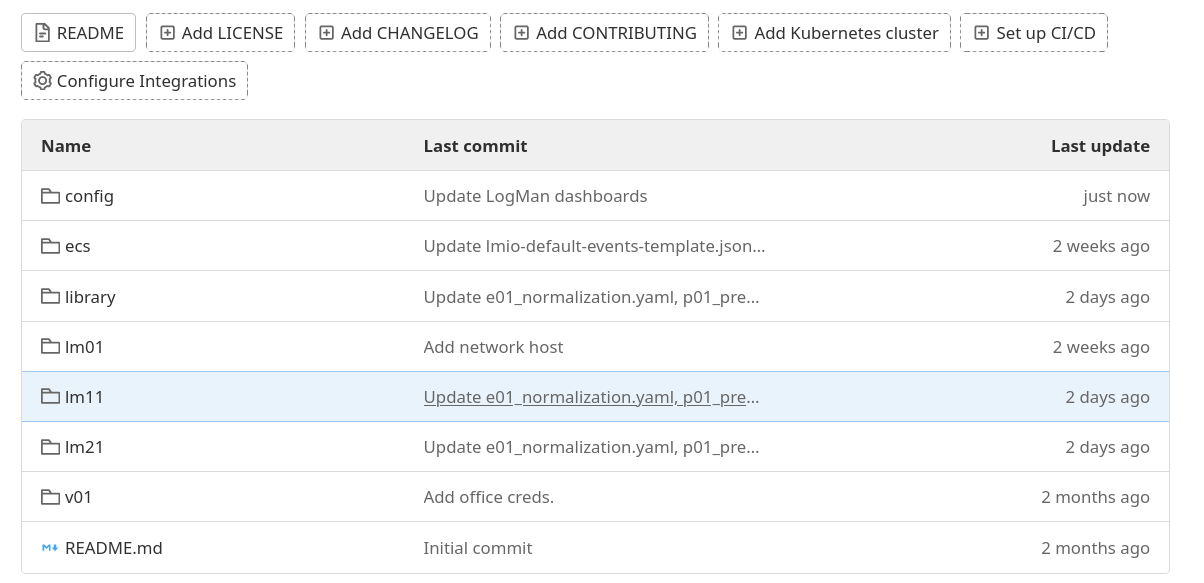
Každý serverový uzel (server) by měl mít samostatnou podsložku na vrcholu GitLab repozitáře.
Dále by měla být složka s LogMan.io library, která obsahuje deklarace pro parsování, korelace atd. skupiny, config, která obsahuje konfiguraci Průzkumníka v UI a dashboardů a složku ecs s šablonami indexů pro ElasticSearch.
Každý partner má přístup k referenčnímu site repozitáři se všemi konfiguracemi včetně parserů a nastavení Průzkumníka, které jsou připravené.
ElasticSearch
Každý uzel v LogMan.io clusteru by měl obsahovat alespoň jeden ElasticSearch master uzel, jeden ElasticSearch data_hot uzel, jeden ElasticSearch data_warm uzel a jeden ElasticSearch data_cold uzel.
Všechny ElasticSearch uzly jsou nasazeny pomocí Docker Compose a jsou součástí site /konfiguračního repozitáře.
Libovolné uzly v clusteru obsahují pouze jeden ElasticSearch master uzel.
Pokud je použitá architektura jednoho serveru, repliky v ElasticSearch by měly být nastaveny na nulu (to bude rovněž poskytnuto po konzultaci s TeskaLabs). Pro ilustraci, viz následující úryvek z Docker Compose souboru, abyste viděli, jak je nasazen ElasticSearch hot uzel:
lm21-es-hot01:
network_mode: host
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.2
depends_on:
- lm21-es-master
environment:
- network.host=lm21
- node.attr.rack_id=lm21 # Nebo název datacentra. Toto je myšleno pro ES, aby efektivně a bezpečně spravoval repliky
# Pro menší instalace -> hostname je v pořádku
- node.attr.data=hot
- node.name=lm21-es-hot01
- node.roles=data_hot,data_content,ingest
- cluster.name=lmio-es # V podstatě "název databáze"
- cluster.initial_master_nodes=lm01-es-master,lm11-es-master,lm21-es-master
- discovery.seed_hosts=lm01:9300,lm11:9300,lm21:9300
- http.port=9201
- transport.port=9301 # Interní komunikace mezi uzly
- "ES_JAVA_OPTS=-Xms16g -Xmx16g -Dlog4j2.formatMsgNoLookups=true"
# - path.repo=/usr/share/elasticsearch/repo # Tato možnost je povolena na vyžádání po instalaci! Není součástí počátečního nastavení (ale máme ji zde, protože je to workshop)
- ELASTIC_PASSWORD=$ELASTIC_PASSWORD
- xpack.security.enabled=true
- xpack.security.transport.ssl.enabled=true
...
Pro více informací o ElasticSearch včetně vysvětlení hot (nedávná, jednodenní data na SSD), warm (starší) a cold uzly viz sekci ElasticSearch Setting.
ZooKeeper & Kafka
Každý serverový uzel v LogMan.io clusteru by měl obsahovat alespoň jeden ZooKeeper a jeden Kafka uzel. ZooKeeper je metadata úložiště dostupné v celém clusteru, kde Kafka ukládá informace o topic konzumentech, názvech topiků atd., a kde LogMan.io ukládá aktuální library a config soubory (viz níže).
Nastavení Kafka a ZooKeeper může být zkopírováno z referenčního site repozitáře a konzultováno s vývojáři TeskaLabs.
Služby
Následující služby by měly být k dispozici alespoň na jednom z LogMan.io uzlů a zahrnují:
nginx(webserver s HTTPS certifikátem, viz referenční site repozitář)influxdb(úložiště metrik, viz Nastavení InfluxDB)mongo(databáze pro přihlašovací údaje uživatelů, seance atd.)telegraf(shromažďuje telemetrické metriky z infrastruktury, burrow a ElasticSearch a odesílá je do InfluxDB, mělo by být nainstalováno na každém serveru)burrow(shromažďuje telemetrické metriky z Kafka a odesílá je do InfluxDB)seacat-auth(TeskaLabs SeaCat Auth je OAuth služba, která ukládá svá data do mongo)asab-library(spravujelibrarys deklaracemi)asab-config(spravuje částconfig)lmio-remote-control(monitoruje jiné mikroslužby jakoasab-config)lmio-commander(nahráválibrarydo ZooKeeper)lmio-dispatcher(přesměrovává data zlmio-eventsalmio-othersKafka topic do ElasticSearch, mělo by běžet alespoň ve třech instancích na každém serveru)
Pro více informací o SeaCat Auth a jeho správě v UI LogMan.io viz Dokumentace TeskaLabs SeaCat Auth.
Pro informace o tom, jak nahrát library z site repozitáře do ZooKeeper, odkazuji na Průvodce LogMan.io Commander.
UI
Následující uživatelská rozhraní by měla být nasazena a zpřístupněna přes nginx. První implementace by měla být vždy konzultována s vývojáři TeskaLabs.
LogMan.io UI(viz LogMan.io Uživatelské rozhraní)Kibana(Průzkumník, vizualizace, dashboardy a monitorování nad ElasticSearch)Grafana(telemetrické dashboardy nad daty z InfluxDB)ZooKeeper UI(správa dat uložených v ZooKeeper)
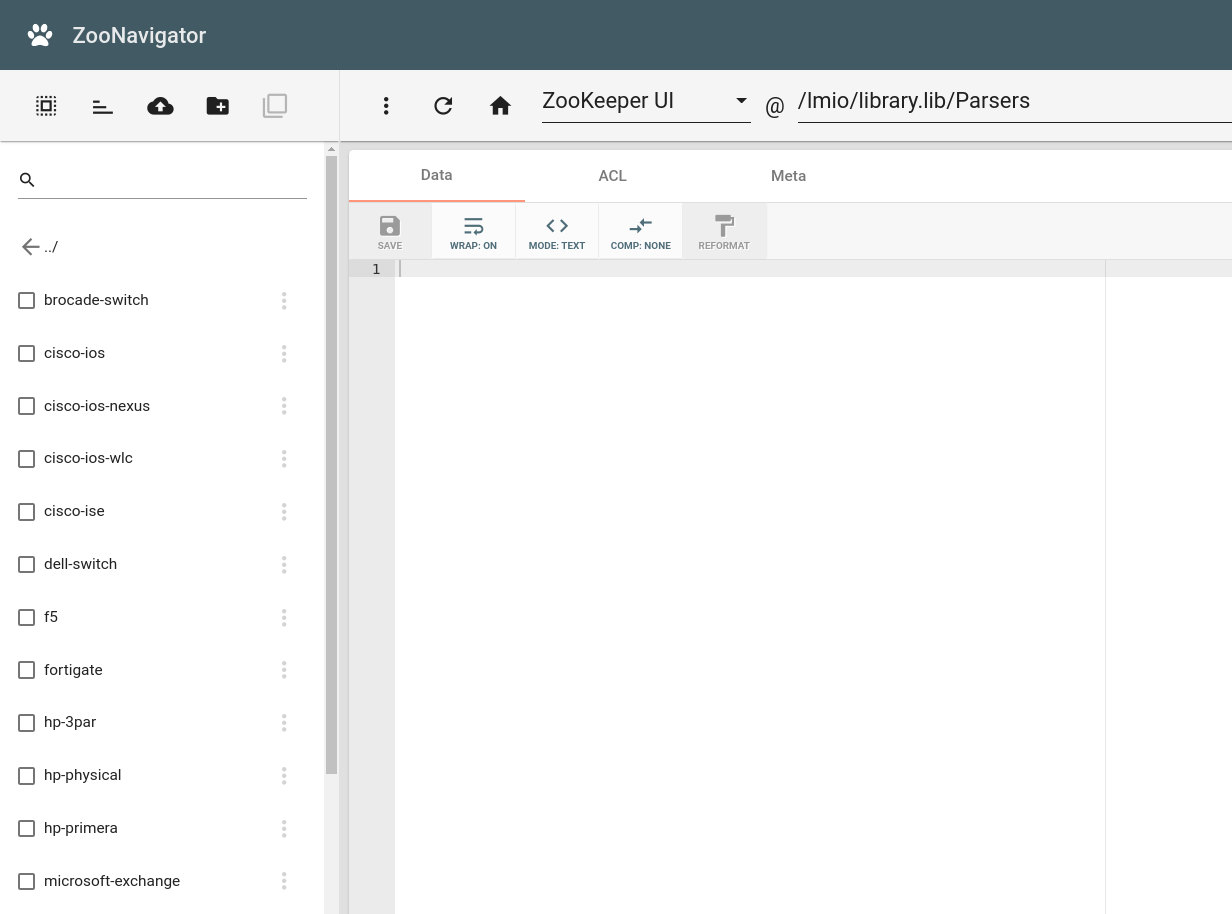
Následující obrázek ukazuje Parsers z library importované do ZooKeeper v ZooKeeper UI:
Nasazení LogMan.io UI
Nasazení LogMan.io UI je částečně poloautomatický proces, pokud je správně nastavené. Takže existuje několik kroků k zajištění bezpečného nasazení UI:
- Nasazení artefaktu UI by mělo být staženo přes
azuresite repozitář poskytnutý vývojáři TeskaLabs. Informace o tom, kde je uložená konkrétní aplikace UI, lze získat z CI/CD obrazu repozitáře aplikace. - Doporučuje se používat
tagovanéverze, ale mohou nastat situace, kdy je požadovánamasterverze. Informace o tom, jak ji nastavit, lze nalézt vdocker-compose.yamlsouboru referenčního site repozitáře. - UI aplikace musí být sladěny se službami, aby byla zajištěna co nejlepší výkonnost (obvykle nejnovější
tagovanéverze). Pokud si nejste jisti, kontaktujte vývojáře TeskaLabs.
Vytvoření tenanta
Každý zákazník je přiřazen jednomu nebo více tenantům.
Tenanty jsou názvy v malých ASCII písmenech, které označují data/logy patřící uživateli a ukládají data každého tenanta do samostatného indexu ElasticSearch.
Všechny event lanes (viz níže) jsou také specifické pro tenanty.
Vytvoření tenanta v SeaCat Auth pomocí LogMan.io UI
Pro vytvoření tenanta se přihlaste do LogMan.io UI s rolí superuživatele, což lze provést prostřednictvím provizionování. Pro více informací o provizionování viz sekci Provizionovací režim dokumentace SeaCat Auth.
V LogMan.io UI přejděte do sekce Auth v levém menu a vyberte Tenants.
Jakmile tam budete, klikněte na možnost Create tenant a napište název tenanta.
Pak klikněte na modré tlačítko a tenant by měl být vytvořen:
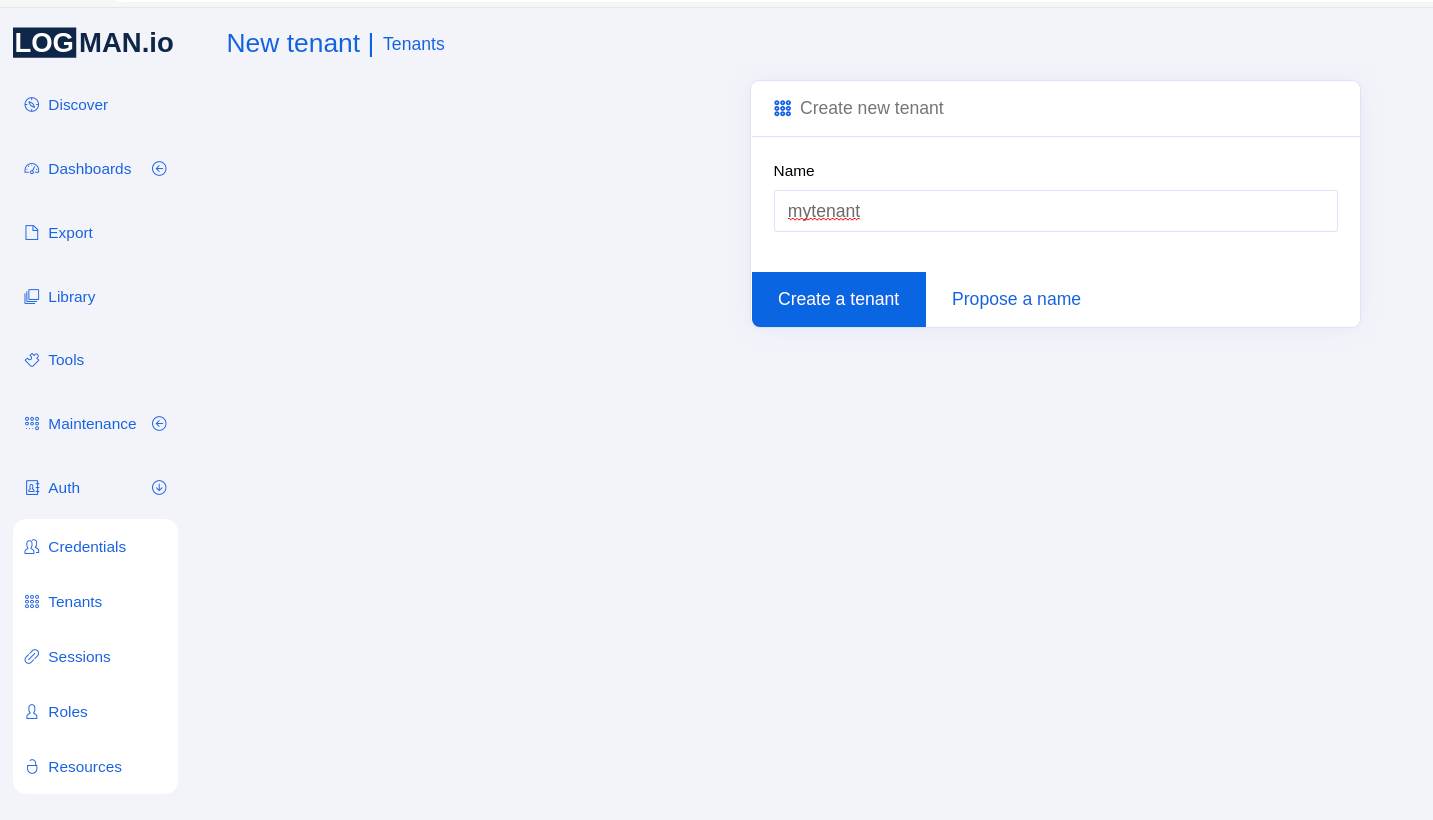
Poté přejděte do Credentials a přiřaďte nově vytvořeného tenanta všem relevantním uživatelům.
Indexy ElasticSearch
V Kibana by měl mít každý tenant šablony indexů pro lmio-tenant-events a lmio-tenant-others indexy, kde tenant je název tenanta (viz referenční site repozitář poskytnutý TeskaLabs).
Šablony indexů lze vložit přes Dev Tools v levém menu Kibana.
Po vložení šablon indexů by měla být manuálně vytvořena ILM (index life cycle management) politika a první indexy, přesně jak je specifikováno v ElasticSearch Setting průvodci.
Kafka
V Kafce není žádné specifické vytvoření tenanta kromě event lanes níže. Nicméně vždy se ujistěte, že jsou správně vytvořeny topic lmio-events a lmio-others.
Následující příkazy by měly být spuštěny v kontejneru Kafka (například: docker exec -it lm11_kafka_1 bash):
# LogMan.io
/usr/bin/kafka-topics --zookeeper lm11:2181 --create --topic lmio-events --replication-factor 1 --partitions 6
/usr/bin/kafka-topics --zookeeper lm11:2181 --create --topic lmio-others --replication-factor 1 --partitions 6
/usr/bin/kafka-topics --zookeeper lm11:2181 --alter --topic lmio-events --config retention.ms=86400000
/usr/bin/kafka-topics --zookeeper lm11:2181 --alter --topic lmio-others --config retention.ms=86400000
# LogMan.io+ & SIEM
/usr/bin/kafka-topics --zookeeper lm11:2181 --create --topic lmio-events-complex --replication-factor 1 --partitions 6
/usr/bin/kafka-topics --zookeeper lm11:2181 --create --topic lmio-lookups --replication-factor 1 --partitions 6
Každý Kafka topic by měl mít alespoň 6 partitionů (což může být automaticky použito pro paralelní konzumaci), což je vhodný počet pro větš