Dashboardy Grafana pro diagnostiku systému¶
Prostřednictvím TeskaLabs LogMan.io můžete přistupovat k dashboardům v Grafana, které monitorují vaše datové pipelines. Tyto dashboardy používejte pro diagnostické účely.
Prvních několik měsíců nasazení TeskaLabs LogMan.io je stabilizační období, během kterého můžete vidět extrémní hodnoty produkované těmito metrikami. Tyto dashboardy jsou obzvlášť užitečné během stabilizace a mohou pomoci s optimalizací systému. Jakmile je váš systém stabilní, extrémní hodnoty obecně indikují problém.
Pro přístup k dashboardům:
- V LogMan.io, přejděte na Nástroje.


-
Klikněte na Grafana. Nyní jste bezpečně přihlášeni do Grafana pomocí vašich uživatelských přihlašovacích údajů pro LogMan.io.
-
Klikněte na tlačítko menu a přejděte na Dashboardy.
-
Vyberte dashboard, který si chcete prohlédnout.
Tipy
- Přejeďte myší nad jakýkoli graf, abyste viděli detaily v konkrétních časových bodech.
- Můžete změnit časový rámec jakéhokoli dashboardu pomocí nástrojů pro změnu časového rámce v pravém horním rohu obrazovky.
Dashboard LogMan.io¶
Dashboard LogMan.io monitoruje všechny datové pipelines ve vaší instalaci TeskaLabs LogMan.io. Tento dashboard vám může pomoci zjistit, pokud například vidíte méně logů, než očekáváte v LogMan.io. Viz Metiky pipeline pro hlubší vysvětlení.
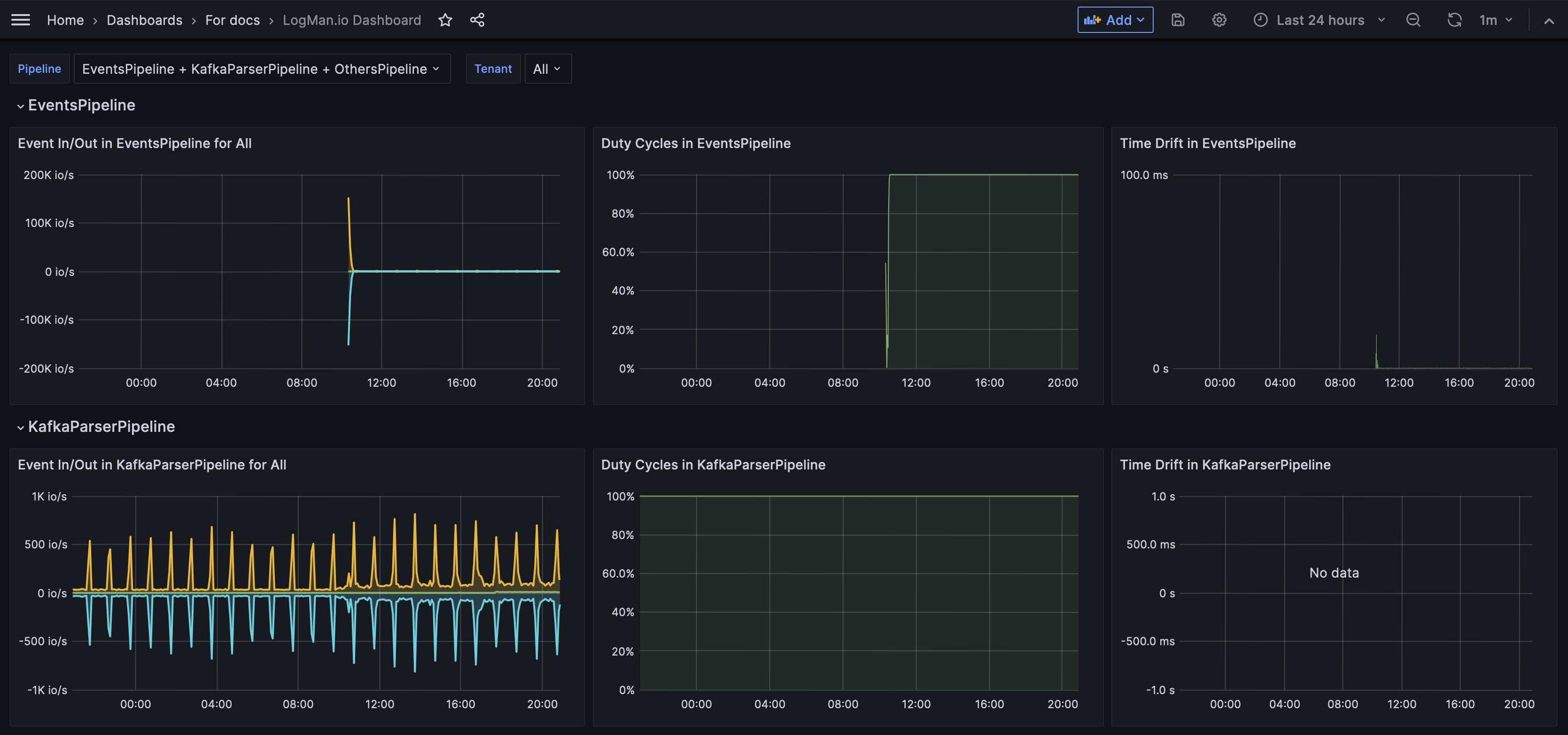
Zahrnuté metriky:
-
Event In/Out: Objem událostí procházejících každou datovou pipeline měřený v operacích vstup/výstup za sekundu (io/s). Pokud pipeline běží hladce, množství In a Out je stejné a linie Drop je nula. To znamená, že stejný počet událostí vstupuje a opouští pipeline a žádná není ztracena. Pokud graf ukazuje, že množství In je větší než množství Out a linie Drop je větší než nula, znamená to, že některé události byly ztraceny a může být problém.
-
Duty cycle: Zobrazuje procento zpracovávaných dat ve srovnání s daty čekajícími na zpracování. Pokud pipeline pracuje podle očekávání, duty cycle je 100%. Pokud je duty cycle nižší než 100%, znamená to, že někde v pipeline je zpoždění nebo překážka, která způsobuje frontu událostí.
-
Time drift: Ukazuje zpoždění nebo lag v zpracování událostí, což znamená, jak dlouho po doručení události je skutečně zpracována. Významné nebo zvýšené zpoždění ovlivňuje vaši kybernetickou bezpečnost, protože brání vaší schopnosti okamžitě reagovat na hrozby. Time drift a duty cycle jsou související metriky. Větší časový drift se objevuje, když je duty cycle pod 100%.
Dashboard přehledu na systémové úrovni¶
Dashboard přehledu na systémové úrovni monitoruje servery zapojené do vaší instalace TeskaLabs LogMan.io. Každý uzel instalace má svou vlastní sekci v dashboardu. Když narazíte na problém ve vašem systému, tento dashboard vám pomůže provést počáteční hodnocení vašeho serveru tím, že vám ukáže, zda je problém spojen s vstup/výstupem, CPU, sítí nebo místem na disku. Pro konkrétnější analýzu se však zaměřte na specifické metriky v Grafana nebo InfluxDB.
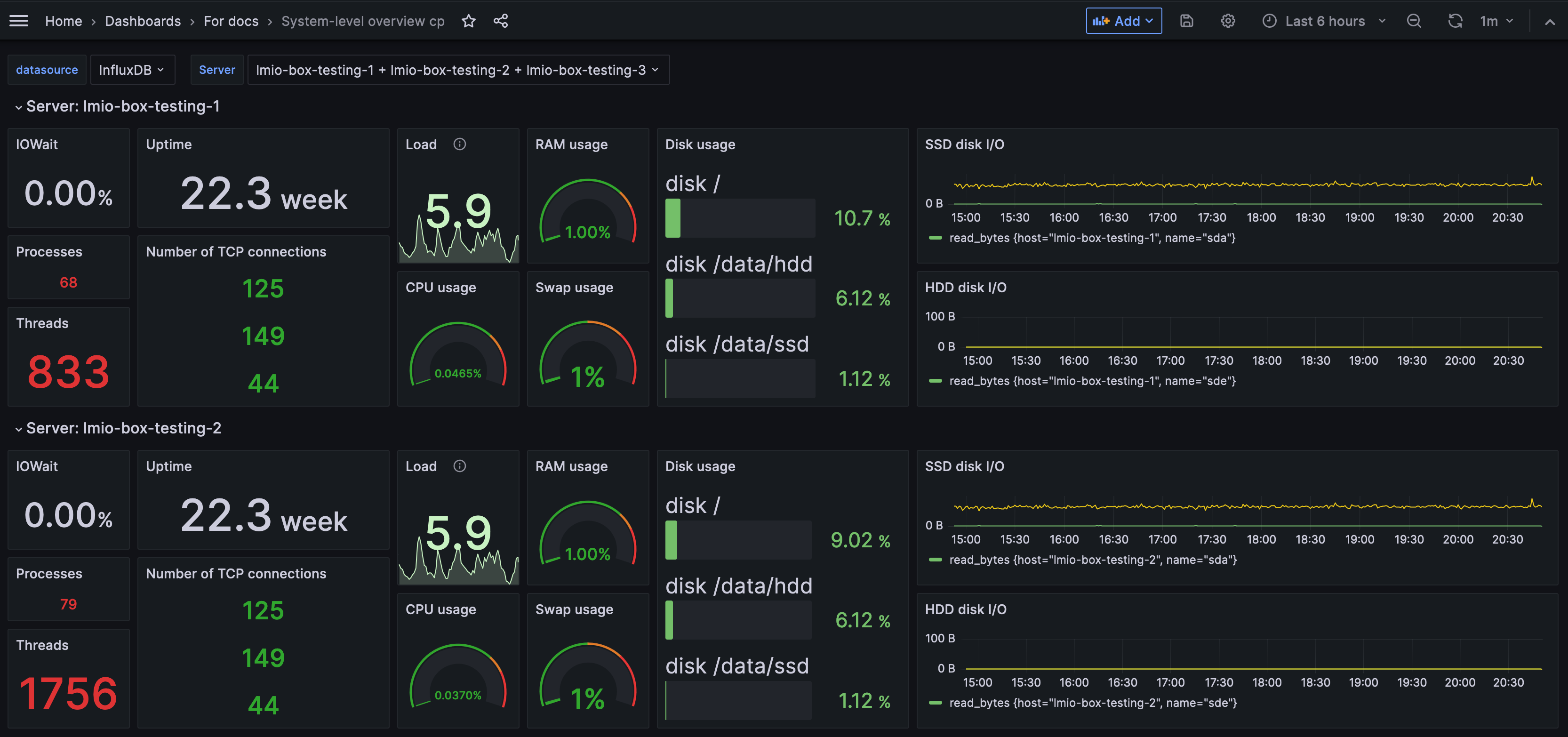
Zahrnuté metriky:
- IOWait: Procento času, kdy CPU zůstává nečinné, zatímco čeká na žádosti o diskový I/O (vstup/výstup). Jinými slovy, IOWait vám říká, kolik času zpracování je plýtváno čekáním na data. Vysoký IOWait, zejména pokud je kolem nebo přesahuje 20% (v závislosti na vašem systému), signalizuje, že rychlost čtení/zápisu disku se stává úzkým hrdlem systému. Rostoucí IOWait naznačuje, že výkon disku omezuje schopnost systému přijímat a ukládat více logů, což ovlivňuje celkovou propustnost a efektivitu systému.
- Uptime: Doba, po kterou server běží bez toho, aby byl vypnut nebo restartován.
- Load: Představuje průměrný počet procesů čekajících v frontě na CPU čas za posledních 5 minut. Je to přímý indikátor, jak zaneprázdněný váš systém je. V systémech s více jádry CPU by tato metrika měla být považována ve vztahu k celkovému počtu dostupných jader. Například zatížení 64 na systému se 64 jádry může být přijatelné, ale nad 100 indikuje vážný stres a neodpovídavost. Ideální zatížení se liší v závislosti na konkrétní konfiguraci a případu použití, ale obecně by nemělo přesahovat 80% celkového počtu jader CPU. Konzistentně vysoké hodnoty zatížení naznačují, že systém se potýká s efektivním zpracováním příchozích logů.
- RAM usage: Procento celkové paměti, která je aktuálně využívána systémem. Udržování využití RAM mezi 60-80% je obecně optimální. Využití nad 80% často vede ke zvýšenému využití swapu, což může zpomalit systém a vést k nestabilitě. Monitorování využití RAM je klíčové pro zajištění, že systém má dostatek paměti k efektivnímu zvládání pracovního zatížení bez použití swapu, který je výrazně pomalejší.
- CPU usage: Přehled procenta kapacity CPU, která je aktuálně používána. Průměruje využití mezi všemi jádry CPU, což znamená, že jednotlivá jádra mohou být pod nebo nadměrně využita. Vysoké využití CPU, zejména nad 95%, naznačuje, že systém čelí výzvám spojeným s kapacitou CPU, kde hlavním omezením je kapacita zpracování CPU. Tato metrika dashboardu pomáhá rozlišit mezi problémy s I/O (kde je úzkým hrdlem přenos dat) a problémy s CPU. Je to klíčový nástroj pro identifikaci úzkých hrdel zpracování, i když je důležité tuto metriku interpretovat společně s ostatními systémovými indikátory pro přesnější diagnostiku.
- Swap usage: Kolik swapového prostoru je využíváno. Swapová partition je vyhrazený prostor na disku použitý jako dočasná náhrada za RAM ("přetečení dat"). Když je RAM plná, systém dočasně ukládá data do swapového prostoru. Vysoké využití swapu, přes přibližně 5-10%, naznačuje, že systému dochází paměť, což může vést ke sníženému výkonu a nestabilitě. Trvalé vysoké využití swapu je znakem toho, že systém potřebuje více RAM, protože silné spoléhání na swapový prostor se může stát hlavním úzkým hrdlem výkonu.
- Disk usage: Měří, kolik kapacity úložiště je aktuálně využíváno. Ve vašem systému pro správu logů je klíčové udržovat využití disku pod 90% a činit opatření, pokud dosáhne 80%. Nedostatečný prostor na disku je častou příčinou selhání systému. Monitorování využití disku pomáhá v proaktivním řízení úložných zdrojů, což zajišťuje dostatek prostoru pro příchozí data a systémové operace. Vzhledem k tomu, že většina systémů je konfigurována k mazání dat po 18 měsících skladování, může se využití disku začít stabilizovat po 18 měsících provozu systému. Více si přečtěte o životním cyklu dat.
Dashboard metrik Elasticsearch¶
Dashboard metrik Elasticsearch monitoruje zdraví Elastic pipeline. (Většina uživatelů TeskaLabs LogMan.io používá databázi Elasticsearch pro ukládání log dat.)
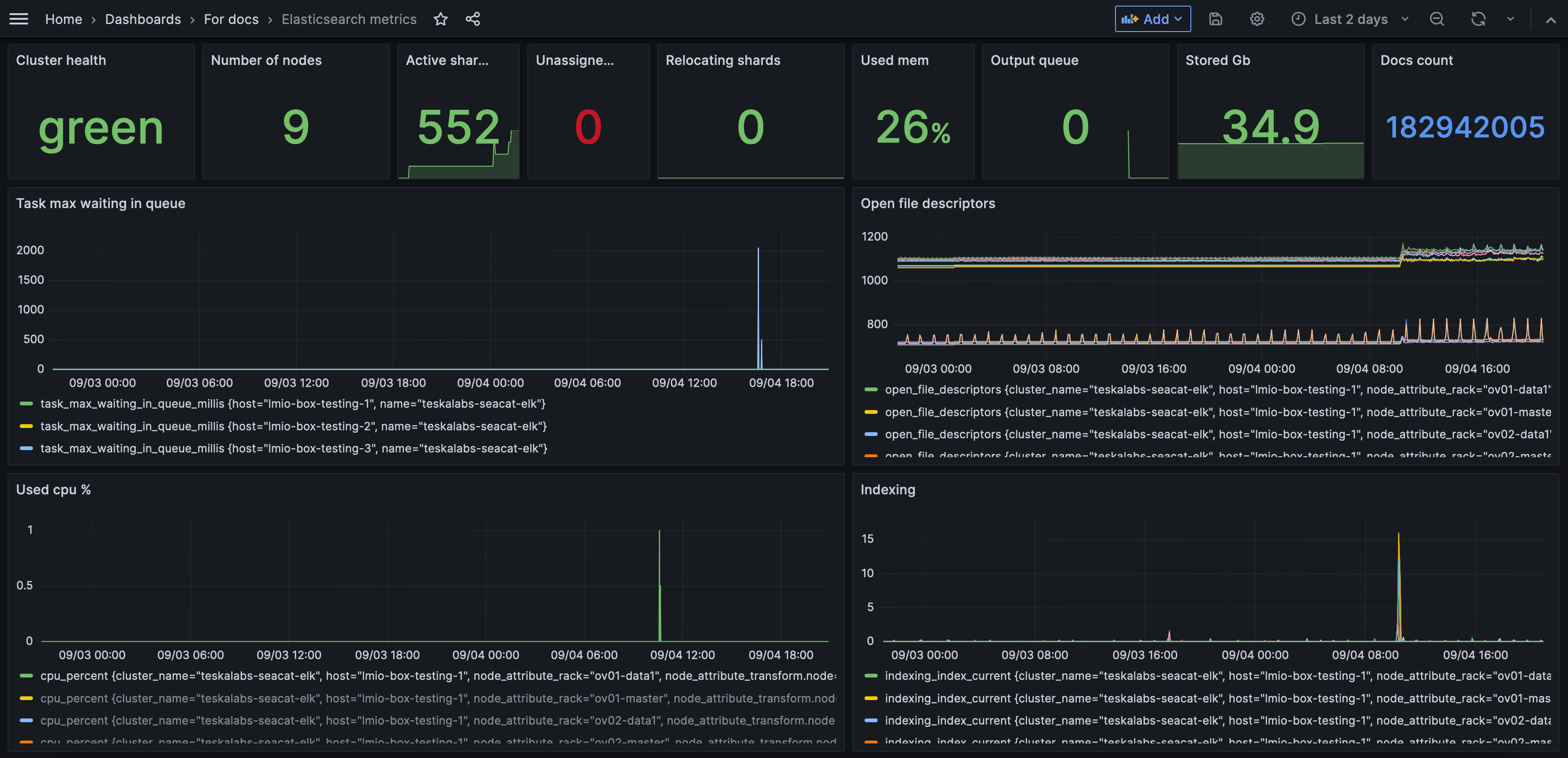
Zahrnuté metriky:
- Cluster health: Zelená je dobrá; žlutá a červená indikují problém.
- Number of nodes: Uzel je jedna instance Elasticsearch. Počet uzlů je, kolik uzlů je součástí vašeho clusteru Elasticsearch v LogMan.io.
- Shards
- Active shards: Počet celkem aktivních shardů. Shard je jednotka, ve které Elasticsearch distribuuje data po celém clusteru.
- Unassigned shards: Počet shardů, které nejsou k dispozici. Mohou být v uzlu, který je vypnutý.
- Relocating shards: Počet shardů, které jsou v procesu přesunu do jiného uzlu. (Možná budete chtít vypnout uzel kvůli údržbě, ale stále chcete, aby všechna vaše data byla dostupná, takže můžete přesunout shard do jiného uzlu. Tato metrika vám řekne, zda jsou nějaké shardy aktivně v tomto procesu a proto zatím nemohou poskytovat data.)
- Used mem: Použitá paměť. Použitá paměť na 100% by znamenala, že Elasticsearch je přetížený a vyžaduje vyšetřování.
- Output queue: Počet úkolů čekajících na zpracování ve výstupní frontě. Vysoký počet může naznačovat významné zpoždění nebo úzké hrdlo.
- Stored GB: Množství diskového prostoru používaného pro ukládání dat v clusteru Elasticsearch. Monitorování využití disku pomáhá zajistit dostatek volného prostoru a plánovat nezbytné rozšíření kapacity.
- Docs count: Celkový počet dokumentů uložených v indexech Elasticsearch. Monitorování počtu dokumentů může poskytnout přehled o růstu dat a požadavcích na správu indexů.
- Task max waiting in queue: Maximální doba, po kterou úkol čekal ve frontě na zpracování. Je užitečná pro identifikaci zpoždění ve zpracování úkolů, což může ovlivnit výkon systému.
- Open file descriptors: Popisovače souborů jsou handly, které umožňují systému spravovat a přistupovat k souborům a síťovým připojením. Monitorování počtu otevřených popisovačů souborů je důležité pro zajištění efektivního řízení systémových zdrojů a prevenci potenciálních úniků handle, které by mohly vést k nestabilitě systému.
- Used cpu %: Procento CPU zdrojů aktuálně používaných Elasticsearch. Monitorování využití CPU pomáhá pochopit výkon systému a identifikovat potenciální úzká místa v CPU.
- Indexing: Míra, jakou jsou nové dokumenty indexovány do Elasticsearch. Vyšší míra znamená, že váš systém může efektivněji indexovat více informací.
- Inserts: Počet nových dokumentů přidávaných do indexů Elasticsearch. Tato linie následuje pravidelný vzor, pokud máte konzistentní počet vstupů. Pokud linie nepravidelně stoupne nebo klesne, může být problém ve vaší datové pipeline, která zabraňuje událostem dosáhnout Elasticsearch.
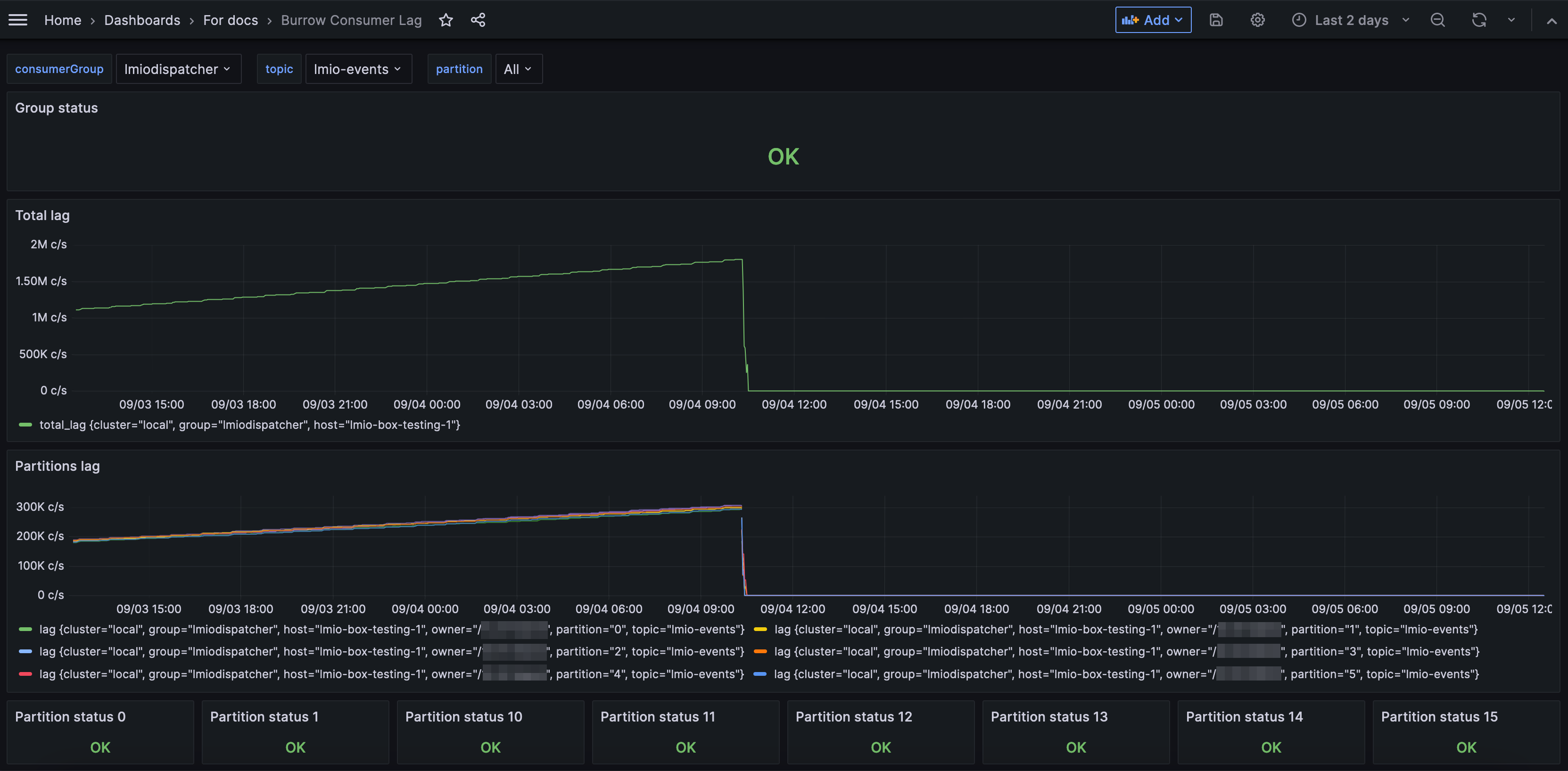
Dashboard zpoždění konzumentů Burrow¶
Dashboard Burrow monitoruje konzumenty a partitiony Apache Kafka. Více se dozvíte o Burrow zde.
Termíny Apache Kafka:
- Consumers: Konzumenti čtou data. Předplácejí si jeden nebo více témat a čtou data v pořadí, ve kterém byla vyprodukována.
- Consumer groups: Konzumenti jsou obvykle organizováni do skupin konzumentů. Každý konzument ve skupině čte z exkluzivních partitionů témat, která si předplácejí, což zajišťuje, že každý záznam je zpracován skupinou pouze jednou, i když více konzumentů čte.
- Partitions: Témata jsou rozdělena na partitiony. Toto umožňuje distribuci dat po celém clusteru, což umožňuje současné čtení a zápis operací.
Zahrnuté metriky:
- Group status: Celkový zdravotní stav skupiny konzumentů. Stav OK znamená, že skupina funguje normálně, zatímco varování nebo chyba mohou indikovat problémy, jako jsou problémy s připojením, selhalí konzumenti nebo nesprávné konfigurace.
- Total lag: V tomto případě lze lag chápat jako frontu úkolů čekajících na zpracování mikroslužbou. Metrika total lag představuje počet zpráv, které byly vyprodukovány do tématu, ale ještě nebyly spotřebovány konkrétním konzumentem nebo skupinou konzumentů. Pokud je lag 0, vše je správně odesláno a není žádná fronta. Vzhledem k tomu, že Apache Kafka má tendenci seskupovat data do dávky, určité množství lagu je často normální. Nicméně, rostoucí lag nebo lag nad přibližně 300 000 (toto číslo závisí na kapacitě vašeho systému, konfiguraci a citlivosti) je důvodem k vyšetřování.
- Partitions lag: Lag jednotlivých partitionů v rámci tématu. Možnost vidět lagu jednotlivých partitionů odděleně vám říká, zda některé partitiony mají větší frontu nebo vyšší zpoždění než jiné, což může indikovat nerovnoměrnou distribuci dat nebo jiné specifické problémy s partitionem.
- Partition status: Stav jednotlivých partitionů. Stav OK naznačuje, že partition funguje normálně. Varování nebo chyby mohou naznačovat problémy jako zastavený konzument, který nečte z partitionu. Tato metrika pomáhá identifikovat specifické problémy s partitionem, které by nemusely být zjevné při pohledu na celkový stav skupiny.