Metriky pipeline¶
Metriky pipeline, nebo měření, monitorují propustnost logů a událostí v pipeline mikroslužeb. Můžete použít tyto metriky pipeline k pochopení stavu a zdraví každé mikroslužby.
Data, která procházejí mikroslužbami, jsou rozložena a měřena v událostech. (Každá událost je jedna zpráva v Kafka a bude mít za následek jeden záznam v Elasticsearch.) Protože události jsou počitatelné, metriky kvantifikují propustnost, což vám umožní posoudit stav a zdraví pipeline.
BSPump
Několik mikroslužeb TeskaLabs je postaveno na technologii BSPump, takže názvy metrik obsahují bspump.
Mikroslužby postavené na BSPump:
Architektura mikroslužeb
Interní architektura každé mikroslužby se liší a může ovlivnit vaši analýzu metrik. Navštivte naši stránku Architecture.
Nejspíše mikroslužby, které produkují nevyrovnané event.in a event.out počítadla metriky bez toho, aby měly chybu, jsou:
- Parser/Parsec - Díky své interní architektuře; parser posílá události do jiné pipeline (Enricher), kde nejsou události započítány v
event.out. - Correlator - Protože korelátor posuzuje události, jak jsou zapojeny do vzorů, často má nižší počet
event.outneževent.in.
Metriky¶
Názvy a tagy v Grafana a InfluxDB
- Metriky pipeline jsou seskupeny pod tagem
measurement. - Metriky pipeline jsou produkovány pro mikroslužby (tag
appclass) a mohou být dále filtrovány pomocí dodatečných tagůhostapipeline. - Každá jednotlivá metrika (například
event.in) je hodnota v tagufield.
Všechny metriky se aktualizují automaticky jednou za minutu jako výchozí nastavení.
bspump.pipeline¶
event.in¶
Popis: Počítá počet událostí vstupujících do pipeline
Jednotka: Počet (událostí)
Interpretace: Sledování event.in v průběhu času vám může ukázat vzory, špičky a trendy v tom, kolik událostí bylo přijato mikroslužbou. Pokud nepřicházejí žádné události, event.in je čára na 0. Pokud očekáváte propustnost, a event.in je 0, je problém v datové pipeline.
event.out¶
Popis: Počítá počet událostí opouštějících pipeline úspěšně
Jednotka: Počet (událostí)
Interpretace: event.out by měla být obvykle stejná jako event.in, ale jsou zde výjimky. Některé mikroslužby jsou konstruovány tak, aby měly buď více výstupů na jeden vstup, nebo aby odváděly data takovým způsobem, že výstup není detekován touto metrikou.
event.drop¶
Popis: Počítá počet událostí, které byly ztraceny nebo zpráv, které byly ztraceny mikroslužbou.
Jednotka: Počet (událostí)
Interpretace: Protože mikroslužby postavené na BSPump nejsou obecně navrženy na ztrácení zpráv, jakoukoli ztrátu je nejspíše chyba.
 Při přejíždění nad grafem v InfluxDB můžete vidět hodnoty jednotlivých čar v jakémkoli bodě času. V tomto grafu můžete vidět, že
Při přejíždění nad grafem v InfluxDB můžete vidět hodnoty jednotlivých čar v jakémkoli bodě času. V tomto grafu můžete vidět, že event.out je rovna event.in a event.drop je rovna 0, což je očekávané chování mikroslužby. Stejný počet událostí opouští pipeline, jaký do ní vstupuje, a žádné události nejsou ztraceny.
warning¶
Popis: Počítá počet varování generovaných v pipeline.
Jednotka: Počet (varování)
Interpretace: Varování vám říkají, že existuje problém s daty, ale pipeline byla stále schopna je zpracovat. Varování je méně závažné než chyba.
error¶
Popis: Počítá počet chyb v pipeline.
Jednotka: Počet (chyb)
Interpretace: Mikroslužby mohou generovat chyby z různých důvodů. Hlavním důvodem pro chybu je, že data neodpovídají očekávání mikroslužby a pipeline nebyla schopna tato data zpracovat.
bspump.pipeline.eps¶
EPS znamená událostí za sekundu.
eps.in¶
Popis: "Události za sekundu dovnitř" - Rychlost událostí úspěšně vstupujících do pipeline
Jednotka: Události za sekundu (rychlost)
Interpretace: eps.in by měla zůstat konzistentní v průběhu času. Pokud eps.in mikroslužby zpomaluje nečekaně v průběhu času, může zde být problém v datové pipeline před mikroslužbou.
eps.out¶
Popis: "Události za sekundu ven" - Rychlost událostí úspěšně opouštějících pipeline
Jednotka: Události za sekundu (rychlost)
Interpretace: Podobně jako u event.in a event.out, eps.in a eps.out by měly být obvykle stejné, ale mohou se lišit v závislosti na mikroslužbě. Pokud události vstupují do mikroslužby mnohem rychleji, než opouštějí, a toto není očekávané chování té pipeline, můžete potřebovat řešit chybu způsobující úzké hrdlo v mikroslužbě.
eps.drop¶
Popis: "Událostech za sekundu ztracených" - rychlost událostí ztracených v pipeline
Jednotka: Události za sekundu (rychlost)
Interpretace: Viz event.drop. Pokud eps.drop rychle roste, a to není očekávané chování mikroslužby, to znamená, že události jsou ztraceny, a existuje problém v pipeline.
 Podobně jako u grafu
Podobně jako u grafu event.in a event.out, očekávané chování většiny mikroslužeb je, že eps.out se rovná eps.in s drop rovno 0.
warning¶
Popis: Počítá počet varován generovaných v pipeline ve specifikovaném časovém období.
Jednotka: Počet (varování)
Interpretace: Varování vám říkají, že existuje problém s daty, ale pipeline byla stále schopna je zpracovat. Varování je méně závažné než chyba.
error¶
Popis: Počítá počet chyb v pipeline ve specifikovaném časovém období.
Jednotka: Počet (chyb)
Interpretace: Mikroslužby mohou generovat chyby z různých důvodů. Hlavním důvodem pro chybu je, že data neodpovídají očekávání mikroslužby a pipeline nebyla schopna tato data zpracovat.
bspump.pipeline.gauge¶
Gauge metrika, procento vyjádřené jako číslo od 0 do 1.
warning.ratio¶
Popis: Poměr událostí, které generovaly varování ve srovnání s celkovým počtem úspěšně zpracovaných událostí.
Interpretace: Pokud poměr varování nečekaně roste, prozkoumejte pipeline pro problémy.
error.ratio¶
Popis: Poměr událostí, které nebyly zpracovány, ve srovnání s celkovým počtem úspěšně zpracovaných událostí.
Interpretace: Pokud poměr chyb nečekaně roste, prozkoumejte pipeline pro problémy. Můžete vytvořit trigger, který vás upozorní, když error.ratio překročí například 5%.
bspump.pipeline.dutycycle¶
Duty cycle (také nazýván power cycle) popisuje, zda pipeline čeká na zprávy (připraven, hodnota 1) nebo není schopna zpracovat nové zprávy (zaneprázdněn, hodnota 0).
Obecně:
- Hodnota 1 je přijatelná, protože pipeline může zpracovat nové zprávy.
- Hodnota 0 signalizuje problém, protože pipeline nemůže zpracovat nové zprávy.
Pochopení myšlenky duty cycle
Můžeme použít lidskou produktivitu k vysvětlení konceptu duty cycle. Pokud osoba vůbec není zaneprázdněná a nemá co dělat, čeká na úkol. Jejich duty cycle čtení je na 100% - tráví všechen svůj čas čekáním a může přijmout více práce. Pokud je člověk zaneprázdněn něčím a nemůže přijmout žádné další úkoly, jejich duty cycle je na 0%.
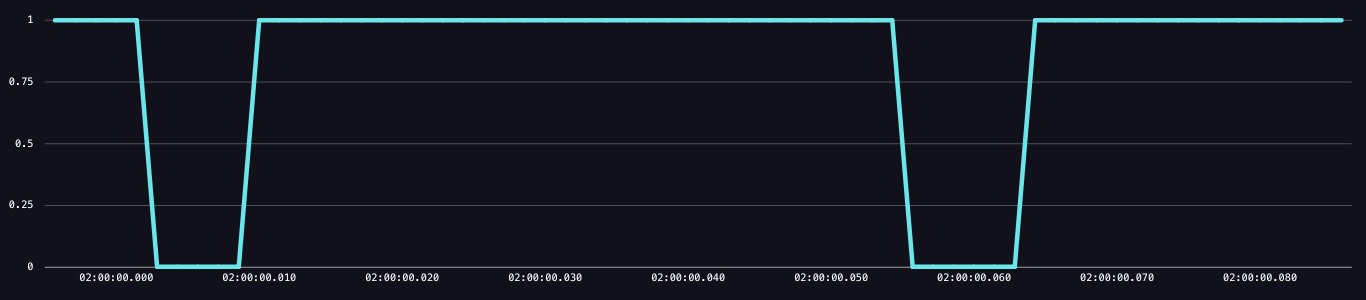 Výše uvedený příklad (není z InfluxDB) ukazuje, jak vypadá změna duty cycle na velmi krátkém časovém měřítku. V tomto příkladu pipeline měla dvě instance, kdy byla na 0, což znamená, že nebyla připravena a nebyla schopna zpracovat nové příchozí události. Mějte na paměti, že duty cycle vašeho systému může kolísat mezi 1 nebo 0 tisíckrát za sekundu; grafy duty cycle
Výše uvedený příklad (není z InfluxDB) ukazuje, jak vypadá změna duty cycle na velmi krátkém časovém měřítku. V tomto příkladu pipeline měla dvě instance, kdy byla na 0, což znamená, že nebyla připravena a nebyla schopna zpracovat nové příchozí události. Mějte na paměti, že duty cycle vašeho systému může kolísat mezi 1 nebo 0 tisíckrát za sekundu; grafy duty cycle ready, které uvidíte v Grafana nebo InfluxDB, už budou agregovány (více níže).
ready¶
Popis: ready agreguje (průměruje) hodnoty duty cycle jednou za minutu. Zatímco duty cycle je vyjádřena jako 0 (false, zaneprázdněný) nebo 1 (true, čekající), metrika ready představuje procento času, kdy duty cycle je na 0 nebo 1. Proto je hodnota ready procento kdekoli mezi 0 a 1, takže graf nevypadá jako typický graf duty cycle.
Jednotka: Procento vyjádřené jako číslo od 0 do 1
Interpretace: Monitorování duty cycle je kritické pro pochopení kapacity vašeho systému. Zatímco každý systém je jiný, obecně ready by mělo zůstat nad 70%. Pokud ready klesne pod 70%, znamená to, že duty cycle klesl na 0 (zaneprázdněný) více než 30% času v tom intervalu, což ukazuje, že systém je velmi zaneprázdněn a vyžaduje určitou pozornost nebo úpravu.
 Nahoře uvedený graf ukazuje, že většinu času byla duty cycle připravena více než 90% času během těchto dvou dnů. Nicméně existují dva body, kdy klesla blízko a pod 70%.
Nahoře uvedený graf ukazuje, že většinu času byla duty cycle připravena více než 90% času během těchto dvou dnů. Nicméně existují dva body, kdy klesla blízko a pod 70%.
timedrift¶
Metrika timedrift slouží jako způsob, jak porozumět, jak moc se časování původů událostí (obvykle @timestamp) liší od toho, co systém považuje za "aktuální" čas. Toto může být užitečné pro identifikování problémů, jako jsou zpoždění nebo nepřesnosti v mikroslužbě.
Každá hodnota je kalkulována jednou za minutu jako výchozí nastavení:
avg¶
Průměr. Toto kalkuluje průměrný časový rozdíl mezi tím, kdy událost skutečně nastala a kdy ji váš systém zaznamenal. Pokud je toto číslo vysoké, může to znamenat stálé zpoždění.
median¶
Medián. Toto vám říká prostřední hodnotu všech timedriftů pro daný interval, poskytuje více "typický" pohled na časovou přesnost vašeho systému. Medián je méně citlivý na extrémy než průměr, protože je to hodnota, nikoli výpočet.
stddev¶
Standardní odchylka. Toto vám dává představu o tom, jak moc timedrift kolísá. Vysoká standardní odchylka může znamenat, že vaše časování je nekonzistentní, což by mohlo být problematické.
min¶
Minimum. Toto ukazuje nejmenší timedrift ve vaší sadě dat. Je užitečné pro pochopení nejlepšího možného scénáře v přesnosti časování vašeho systému.
max¶
Maximum. Toto ukazuje největší časový rozdíl. To vám pomáhá pochopit nejhorší scénář, což je klíčové pro identifikování horních hranic potenciálních problémů.
 V tomto grafu časového driftu vidíte špičku zpoždění předtím, než se pipeline vrátí do normálu.
V tomto grafu časového driftu vidíte špičku zpoždění předtím, než se pipeline vrátí do normálu.
commlink¶
commlink je komunikační spojení mezi LogMan.io Collectorem a LogMan.io Receiverem. Tyto metriky jsou specifické pro data zasílaná z mikroslužby Collector do mikroslužby Receiver.
Tagy: ActivityState, appclass (pouze LogMan.io Receiver), host, identity, tenant
- bytes.in: byty, které vstupují do LogMan.io Receiveru
- event.in: události, které vstupují do LogMan.io Receiveru
logs¶
Počet logů, které procházejí mikroslužbami.
Tagy: appclass, host, identity, instance_id, node_id, service_id, tenant
- critical: Počet kritických logů
- errors: Počet chybových logů
- warnings: Počet varovných logů