Dokumentace SP-Langu¤
Vítejte u dokumentace SP-Langu. SP-Lang je zkratka pro Stream Processing Language. SP-Lang je navržen jako intuitivní a snadno použitelný jazyk i pro lidi, kteří nemají zkušenosti s programováním. Snažíme se, aby jeho používání bylo stejně jednoduché jako používání maker v tabulkovém procesoru nebo jazyka SQL, což vám umožní provádět výkonné úlohy zpracování dat s minimálním úsilím.
Hlavním cílem jazyka SP-Lang je, aby za vás udělal mnoho těžké práce, takže se můžete soustředit na to, čeho chcete dosáhnout, a ne se starat o detaily, jak to realizovat. Tento nízkoúrovňový přístup vám umožní rychle začít pracovat, aniž byste se museli učit spoustu složitých programovacích konceptů.
Doufáme, že vám tato dokumentace poskytne všechny informace, které potřebujete k tomu, abyste mohli začít pracovat s naším jazykem a začít využívat jeho výkonné možnosti proudového zpracování. Děkujeme, že jste si vybrali náš jazyk, a těšíme se na to, co s ním dokážete!
Vyrobeno s v TeskaLabs
SP-Lang je technologie vytvářená ve společnosti TeskaLabs.
Úvod¤
SP-Lang je funkcionální jazyk, který používá syntaxi YAML.
SP-Lang poskytuje velmi vysoký výkon, protože je zkompilován do strojového kódu. To mu spolu s rozsáhlými optimalizacemi dává výkon srovnatelný s jazyky jako jsou C, Go nebo Rust; tedy nejvýše dosažitelný.
Z tohoto důvodu je SP-Lang přirozeným kandidátem na nákladově efektivní zpracování masivních datových toků v cloudu nebo v on-premise aplikacích.
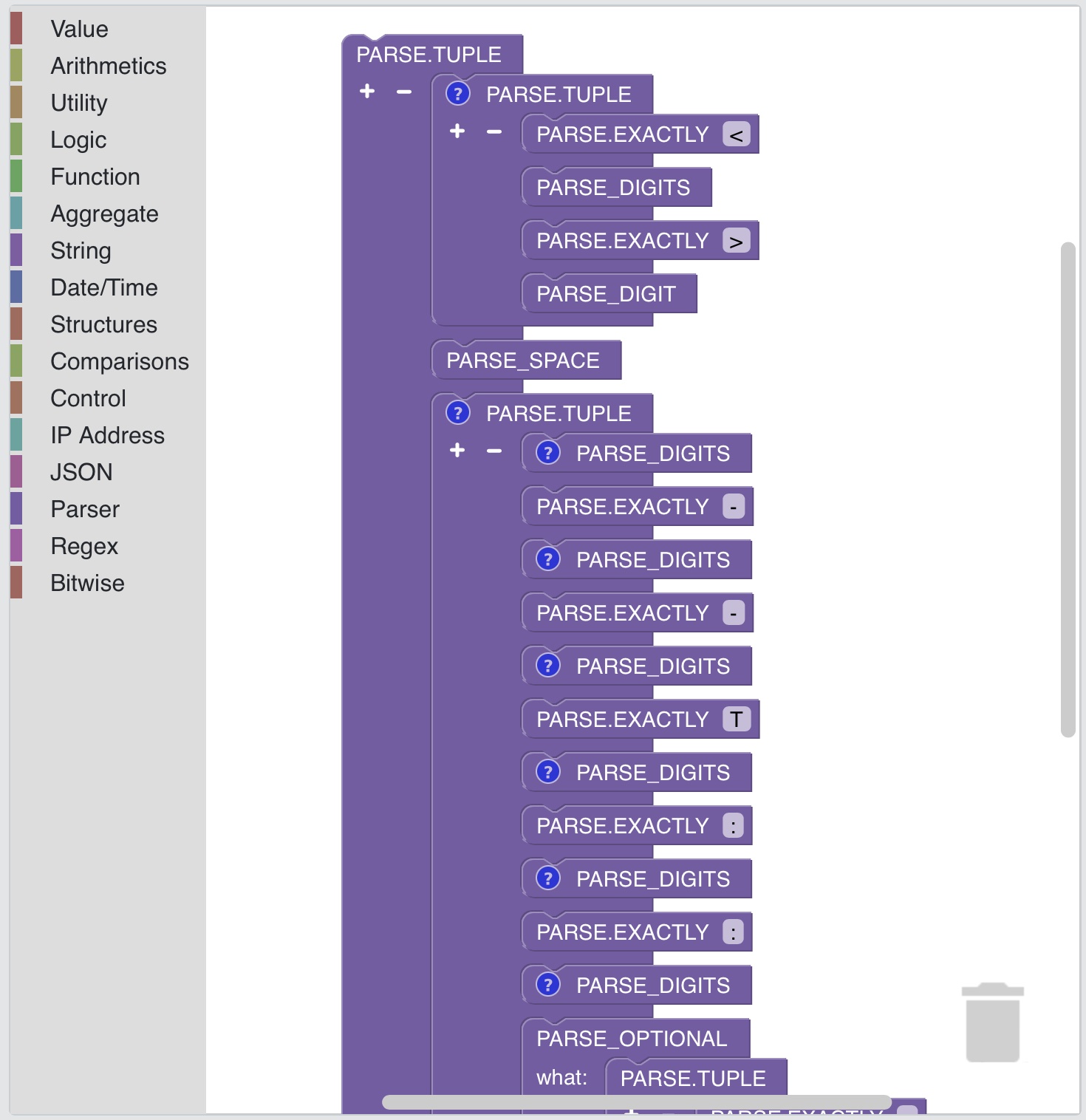
Hello world! v jazyce SP
!ADD
- Hello
- " "
- world
- "!"
Stejný příklad ve vizuální podobě SP-Langu
Pro první seznámení s jazykem SP-Lang vyzkoušejte náš tutoriál.
Vlastnosti jazyka SP-Lang¤
- 📜 Deklarativní jazyk
- 🔗 Funkcionální jazyk
- 🔐 Silně typovaný
- 💡 Typová inference
- 🐍 Interpretován v jazyce Python
- 🚀 Kompilován pomocí LLVM
- Syntaxe je založena na YAML
Věnování¤
Tato práce je věnována památce mé matky, jejíž víra ve mne byla stejně pevná jako bezpodmínečná. Ačkoli technická stránka návrhu doménového jazyka byla mimo její sféru, její neochvějná víra ve mne byla majákem, který mě provázel.
Její duch, láska a houževnatost ve mně zůstávají, inspirují mě a pohání kupředu. Doufám, že tento jazyk, výtvor mé práce a lásky, je svědectvím jejího nezdolného ducha.
Rád bych také vyjádřil upřímnou vděčnost všem přispěvatelům, jejichž obětavost a odborné znalosti pomohly utvářet tento projekt. Díky vaší spolupráci bylo možné tuto technologii vytvořit.
Děkuji ti, mami.
Tohle je pro tebe.
Aleš Teska
Syntaxe jazyka SP¤
Info
Syntaxe SP-Lang používá [YAML 1.2](https://yaml.org/spec/1.2)
Komentáře¤
Komentář je označen indikátorem #.
# Tento soubor neobsahuje žádný SP-Lang
# Pouze komentáře.
Čísla¤
Celá čísla¤
kanonický zápis: 12345
kladné číslo: +12345
záporné číslo: -12345
osmičkový zápis: 0o14
hexadecimální zápis: 0xC
Desetinná čísla¤
pevný zápis: 1230.15
kanonický zápis: 1.23015e+3
exponenciální zápis: 12.3015e+02
záporné nekonečno: -.inf
není číslo: .nan
Řetězce¤
řetězec: '012345'
řetězec bez uvozovek: Řetězec můžete zadat i bez uvozovek.
emoji: 😀🚀⭐
Řetězce s uvozovkami:
unicode: "\u263A"
control: "\b1998\t1999\t2000\n"
hexadecimální esc: "\x0d\x0a je \r\n"
singl: '"Nazdar!" zvolal.'
citováno: '# Toto není ''komentář''.'
Víceřádkové řetězce:
|
_____ _____ _
/ ____| __ \ | |
| (___ | |__) |_____| | __ _ _ __ __ _
\___ \| ___/______| | / _` | '_ \ / _` |
____) | | | |___| (_| | | | | (_| |
|_____/|_| |______\__,_|_| |_|\__, |
__/ |
|___/
Doslovný styl (označený |) zachovává počáteční mezery.
>
Mark McGwire's
year was crippled
by a knee injury.
Složený styl (označený >) odstraňuje případné odsazení YAML.
Pravdivostní hodnoty (booleans)¤
True boolean: true
False boolean: false
Výrazy¤
Všechny výrazy SP-Lang (alias funkce) začínají na !, výrazy SP-Lang jsou tedy tagy YAML (!TAG).
Výrazy mohou být těchto typů:
- Mapování (Mapping)
- Posloupnost (Sequence)
- Skalár (Scalar)
Mapovací výrazy¤
Příklad:
!ENDSWITH
what: FooBar
postfix: Bar
Příklad použití ve formě flow :
!ENDSWITH {what: FooBar, postfix: Bar}
Specifikace YAML
Viz kapitola 10.2. Styly mapování.
Sekvenční výrazy¤
Příklad:
!ADD
- 1
- 2
- 3
Příklad použití ve formě flow :
!ADD [1, 2, 3]
Specifikace YAML
Viz kapitola 10.1. Styly sekvencí.
Sekvenční výraz lze definovat také pomocí argumentu with:
!ADD
with: [1, 2, 3]
Tip
Jedná se vlastně o mapovací formu sekvenčního výrazu.
Skalární výrazy¤
Příklad:
!ITEM EVENT brambory
Specifikace YAML
Viz kapitola [9. Skalární styly](https://yaml.org/spec/1.1/#id903915)
Kotvy a aliasy¤
SP-Lang využívá YAML kotvy a aliasy.
To znamená, že se můžete odkazovat na výsledek jiného výrazu pomocí kotvy.
Kotva je řetězec začínající znakem "&".
Výsledek výrazu anotovaného kotvou lze pak znovu použít pomocí aliasu, což je řetězec začínající na "*" následovaný jménem kotvy.
Na jednu kotvu se může odkazovat více aliasů.
Příklad:
!ADD
- 1
- &subcount !MUL
- 2
- 3
- *subcount
- *subcount
Výsledek je roven 1+(2*3)+(2*3)+(2*3), tedy 19.
Struktura souboru SP-Lang¤
SP-Lang používá tři pomlčky (---) k oddělení výrazů od obsahu dokumentu.
Slouží také k signalizaci začátku SP-Langu.
Tři tečky ("...") označují konec souboru bez začátku nového, pro použití v komunikačních kanálech.
Přípona souboru SP-Lang je .yaml.
Příklad souboru SP-Lang:
---
# Proveďme nějaké základní matematické výpočty
!MUL
- 1
- 2
- 3
Poznámka
Soubor SP-Lang vždy začíná řádkem ---.
Info
Jeden soubor může obsahovat více výrazů pomocí oddělovače YAML (---).
Tutoriál k SP-Langu¤
Úvod¤
Vítejte u tutoriálu k SP-Langu. SP-Lang, zkratka pro Stream Processing Language, je doménově specifický jazyk (DSL). Je založen na YAML, člověkem čitelném jazyku pro serializaci dat. Cílem tohoto tutoriálu je představit základní prvky jazyka SP-Lang.
Hello World¤
Začneme jednoduchým příkladem:
---
Hello world!
V jazyce SP-Lang signalizují trojité pomlčky (---) začátek kódu.
Hello world! zde je hodnota, kterou chcete vrátit.
V tomto případě je to náš přátelský pozdrav "Hello world!" ("Ahoj světe!").
SP-Lang je založen na YAMLu¤
SP-Lang je postaven na YAML (Yet Another Markup Language). YAML klade důraz na jednoduchost a čitelnost, což z něj činí skvělý základ pro SP-Lang.
Important
Jazyk YAML ve velké míře stojí na odsazování, které je významné v jeho syntaxi. Jako osvědčený postup doporučujeme používat pro odsazení dvě mezery. Upozorňujeme, že v jazyce YAML nejsou podporovány znaky TAB.
Komentáře¤
Při psaní kódu je užitečné zanechávat komentáře. Usnadníte tak ostatním (a svému budoucímu já) pochopit, co váš kód dělá.
# Toto je komentář.
---
Hello world!
Komentáře v SP-Langu začínají znakem #.
SP-Lang ignoruje vše, co následuje za # na stejném řádku, což je užitečné pro přidávání poznámek nebo popisování kódu.
Výrazy SP-Lang¤
Výrazy (Expressions) v jazyce SP-Lang jsou příkazy, které provádějí operace. Podívejme se na příklad s aritmetickými výrazy:
Tento kód sečte dvě čísla, konkrétně vypočítá 5+8.
---
!ADD
- 5
- 8
Výše uvedený výraz sečte dvě čísla, 5 a 8, a získá výsledek 13.
Výrazy v jazyce SP-Lang začínají vykřičníkem (!).
Tip
Výraz "Expression" je alternativní výraz pro funkci.
V tomto příkladu je !ADD výraz pro aritmetické sčítání, které sečte zadaná čísla.
Čísla, která chcete sečíst, jsou zadána jako seznam, protože !ADD je výraz pro posloupnost.
To znamená, že může sčítat více vstupních hodnot:
---
!ADD
- 5
- 8
- 9
- 15
Tento seznam vstupních hodnot je vytvořen pomocí pomlčky - na začátku řádku obsahujícího hodnotu.
Každý řádek představuje jednotlivou položku seznamu.
Výrazy můžete psát také stručněji pomocí "flow formy", kterou lze libovolně kombinovat s výchozím stylem kódu SP-Lang:
---
!ADD [5, 8, 9, 15]
Mapovací výrazy¤
Dalším typem výrazu je mapovací výraz (mapping expression). Namísto seznamu vstupů používají mapovací výrazy jména vstupů, která lze nalézt v dokumentaci výrazu.
---
!ENDSWITH
what: "FooBar"
postfix: "Bar"
Výraz !ENDSWITH kontroluje, zda hodnota zadaná na vstupu what končí hodnotou zadanou na vstupu postfix. Pokud ano, vrátí true, pokud ne, vrátí false.
I na mapovací výrazy lze použít flow formu:
---
!ENDSWITH {what: "FooBar", postfix: "Bar"}
Skládání výrazů¤
SP-Lang umožňuje kombinovat výrazy a vytvářet tak složitější a výkonnější řešení. Výstup jednoho výrazu můžete vzít za základ pro vstup do jiného výrazu.
---
!MUL
- 5
- !ADD [6, 2, 3]
- 9
- !SUB [10, 5]
Tento příklad je ekvivalentní aritmetické operaci 5 * (6 + 2 + 3) * 9 * (10 - 5).
Argumenty¤
Argumenty jsou způsob, jakým do jazyka SP-Lang předáváme data. V závislosti na kontextu volání může mít výraz žádný, jeden nebo více argumentů. Každý argument má jedinečné jméno.
K hodnotě argumentu můžete přistupovat pomocí výrazu !ARG.
V následujícím příkladu je argumentem výraz name:
---
!ADD ["Hi ", !ARG name, "!"]
Tento výraz bere hodnotu name a vloží ji do řetězce, čímž se vytvoří pozdrav.
Závěr¤
V tomto tutoriálu jsme se seznámili se základy jazyka SP-Lang, včetně toho, jak psát jednoduché výrazy, složené výrazy a jak používat argumenty. S těmito základy jste připraveni začít prozkoumávat složitější definice v jazyce SP-Lang. Při dalším pokračování nezapomeňte hojně využívat dokumentaci, abyste porozuměli různým výrazům a jejich požadovaným vstupům.
Mnoho zdaru při programování!
Výrazy ↵
Agregační výrazy¤
Agregační výraz je typ funkce, která provádí výpočty nad množinou hodnot a jako výsledek vrací jednu hodnotu. Tyto výrazy se běžně používají k shrnutí nebo zhuštění dat.
!AVG: Průměr (aritmetický průměr)¤
Vypočítá aritmetický průměr.
Typ: Sequence
Info
Více informací o aritmetickém průměru na Wikipedii.
Příklad
!AVG
- 6
- 2
- 4
Výpočet průměru (6+2+4)/3, výsledek je 4.
!MAX: Maximum¤
Vrací maximální hodnotu z posloupnosti.
Typ: Sequence
Příklad
!MAX
- 1.5
- 2.6
- 5.1
- 3.05
- 4.45
Výsledek tohoto výrazu je 5.1.
!MIN: Minimum¤
Vrací minimální hodnotu z posloupnosti.
Typ: Sequence
Příklad
!MIN
- 2.6
- 3.05
- 4.45
- 0.5
- 5.1
Výsledek tohoto výrazu je 0.5.
!COUNT: Počet položek¤
Spočítá počet položek v seznamu.
Typ: Sequence
Příklad
!COUNT
- Frodo Pytlík
- Samvěd Křepelka
- Gandalf
- Legolas
- Gimli
- Aragorn
- Boromir z Gondoru
- Smělmír Brandorád
- Pipin Bral
Výsledek tohoto výrazu je 9.
!MEDIAN: Medián (prostřední hodnota)¤
Medián je prostřední hodnota v seznamu čísel; polovina hodnot je větší než medián a polovina je menší než medián. Pokud má seznam sudý počet prvků, je medián aritmetickým průměrem dvou prostředních hodnot.
Typ: Sequence
Info
Více informací o medián na Wikipedii.
Příklad
!MEDIAN
- 1
- 4
- -1
- 9
- 101
Výsledek výrazu je 4.
!MODE: Modus (hodnota vyskytující se nejčastěji)¤
Modus je označení pro hodnotu nebo hodnoty, které se v seznamu vyskytují nejčastěji. Lze ji použít k vyjádření centrální tendence souboru dat.
Typ: Sequence
Info
Více informací o mode na Wikipedii.
Příklad
!MODE
- 10
- 10
- -20
- -20
- 6
- 10
Výsledek výrazu je 10.
!RANGE: Rozdíl mezi největší a nejmenší hodnotou¤
Range určuje rozdíl mezi největší a nejmenší hodnotou. V češtině je pro něj též užívaný termín "variační rozpětí".
Typ: Sequence
Info
Více informací o range na Wikipedii.
Příklad
!RANGE
- 1
- 3
- 4
- 20
- -1
Aritmetické výrazy¤
!ADD: Sčítání¤
Typ: Sequence
Výraz je definovaný pro následující typy:
- Čísla (celá čísla a desetinná čísla)
- Řetězce
- Seznamy
- Množiny
- Tuples
- Records (záznamy)
Příklad
!ADD
- 4
- -5
- 6
Vypočítá 4+(-5)+6, výsledek je 5.
!SUB: Odčítání¤
Typ: Sequence
Příklad
!SUB
- 3
- 1
- -5
Vypočítá 3-1-(-5), výsledkem je 7.
!MUL: Násobení¤
Typ: Sequence
Příklad
!MUL
- 7
- 11
- 13
Vypočítá 7*11*13, výsledkem je 1001 (což je shodou okolností Šahrazádino číslo).
!DIV: Dělení¤
Typ: Sequence
Příklad
!DIV
- 21
- 1.5
Vypočítá 21/1.5, výsledkem je 14.0.
Dělení nulou¤
Dělení nulou vede k chybě, která se může kaskádovitě projevit ve výrazu.
Pro řešení této situace lze použít výraz !TRY.
První položkou výrazu !TRY je !DIV, který může způsobit chybu dělení nulou.
Druhou položkou je hodnota, která bude vrácena, pokud k takové chybě dojde.
!TRY
- !DIV
- !ARG input
- 0.0
- 5.0
!MOD: Zbytek po dělení (modulo)¤
Typ: Sequence
Vypočítá znaménkový zbytek dělení (neboli výsledek operace modulo).
Info
Více informací o operaci modulo na Wikipedii.
Příklad
!MOD
- 21
- 4
Vypočítá 21 mod 4, výsledkem je 1.
Příklad
!MOD
- -10
- 3
Vypočítá -10 mod 3, výsledkem je 2.
!POW: Exponentiation¤
Typ: Sequence
Výpočet exponentu.
Příklad
!POW
- 2
- 8
Vypočítá 2^8, výsledkem je 16.
!ABS: Absolutní hodnota¤
Typ: Mapping
!ABS
what: <x>
Vypočítá absolutní hodnotu vstupu x, což je nezáporná hodnota x bez ohledu na její znaménko.
Příklad
!ABS
what: -8,5
Výsledkem je hodnota 8.5.
Bitové operace¤
Bitové posuny ("bit shifts") zachází s hodnotou jako se sérií bitů, umožňuje přesunout nebo posunout binární číslice doleva nebo doprava.
Existují také bitové výrazy !AND, !OR a !NOT, viz kapitolu Logické výrazy.
!SHL: Logický posun doleva¤
Typ: Mapping.
!SHL
what: <...>
by: <...>
Tip
Levý posun lze použít jako rychlé násobení čísly 2, 4, 8 atd.
Příklad
!SHL
what: 9
by: 2
9 je reprezentovaná binární hodnotou 1001. Levý logický posun posune bity doleva o 2 pozice. Výsledkem je 100100, což je v desítkovém zápise 36. To je 9 * (2^2). To je stejný výsledek jako 9 * (2^2).
!SHR: Logický posun doprava¤
Typ: Mapping.
!SHR
what: <...>
by: <...>
Tip
Pravý posun lze použít jako rychlé dělení čísly 2, 4, 8 atd.
Příklad
!SHR
what: 16
by: 3
16 je reprezentovaná 10000. Logický posun posune bity doprava o 3. Výsledkem je 10, tedy 2 v desítkovém zápisu. To je stejný výsledek jako 16 / (2^3).
!SAL: Aritmetický posun doleva¤
Typ: Mapping.
!SAL
what: <...>
by: <...>
Příklad
!SAL
what: 60
by: 2
!SAR: Pravý aritmetický posun¤
Typ: Mapping.
!SAR
what: <...>
by: <...>
!ROL: Kruhový posun doleva¤
Typ: Mapping.
!ROL
what: <...>
by: <...>
!ROR: Kruhový posun doprava¤
Typ: Mapping.
!ROR
what: <...>
by: <...>
Porovnávací výrazy¤
Testovací výraz vyhodnotí vstupy a na základě výsledku testu vrátí logickou hodnotu true nebo false.
!EQ: Rovná se¤
Příklad
!EQ
- !ARG count
- 3
Porovnává argument count s 3, vrací count == 3.
!NE: Nerovná se¤
Typ: Sequence.
Jedná se o zápornou obdobu !EQ.
Příklad
!NE
- !ARG name
- Frodo
Porovnává argument name s Frodo, vrací name != Frodo.
!LT: Menší než¤
Typ: Sequence.
Příklad
!LT
- !ARG count
- 5
Příklad testu count < 5.
!LE: Menší nebo rovno¤
Typ: Sequence.
Příklad
!LE
- 2
- !ARG počet
- 5
Příklad testu rozsahu 2 <= count <= 5.
!GT: Větší než¤
Typ: Sequence.
Příklad
!GT [!ARG count, 5]
Příklad testu count > 5 pomocí kompaktní formy YAMLu.
!GE: Větší nebo rovno¤
Typ: Sequence.
Příklad
!GT
- !ARG count
- 5
Příklad testu count >= 5.
!IN: Test výskytu¤
Typ: Mapping.
!IN
what: <...>
where: <...>
Výraz !IN se používá ke kontrole, zda hodnota se what vyskytuje v hodnotě where, nebo ne.
Jako hodnotu where lze uvést řetězec, kontejner (seznam, množina, slovník), strukturní typ atd.
Vyhodnotí se na true, pokud najde hodnotu what v zadané hodnotě where, a na false v opačném případě.
Příklad
!IN
what: 5
where:
- 1
- 2
- 3
- 4
- 5
Zkontroluje přítomnost hodnoty 5 v seznamu where. Vrátí true.
Příklad
!IN
what: "Willy"
where: "John Willy Boo"
Zkontroluje přítomnost podřetězce Willy v hodnotě John Willy Boo. Vrátí true.
Řídicí výrazy¤
SP-Lang nabízí celou řadu řídicích výrazů.
!IF: Jednoduché podmíněné větvení¤
Typ: Mapping.
Výraz !IF je rozhodovací výraz, který vede vyhodnocení k rozhodování na základě zadaného testu.
!IF
test: <expression>
then: <expression>
else: <expression>
Na základě hodnoty test se vyhodnotí větev:
thenv případětest !EQ trueelsev případětest !EQ false
Oba případy then a else musejí vracet stejný typ, který bude zároveň typem návratové hodnoty !IF.
Příklad
!IF
test:
!EQ
- !ARG input
- 2
then:
It is two.
else:
It is NOT two.
!WHEN: Násobné větvení¤
Typ: Sequence.
Výraz !WHEN je podstatně silnější než výraz !IF.
Jednotlivé případy mohou odpovídat mnoha různým vzorům, včetně intervalových shod, tuples atd.
!WHEN
- test: <expression>
then: <expression>
- test: <expression>
then: <expression>
- test: <expression>
then: <expression>
- ...
- else: <expression>
Pokud není zadáno else, pak WHEN vrací False.
Příklad
Příklad použití !WHEN pro přesnou shodu, shodu rozsahu a nastavenou shodu:
!WHEN
# Přesná shoda hodnot
- test:
!EQ
- !ARG key
- 34
pak:
"třicet čtyři"
# Shoda rozsahu
- test:
!LT
- 40
- !ARG key
- 50
then:
"čtyřicet až padesát (bez krajních hodnot)"
# In-set match
- test:
!IN
what: !ARG key
where:
- 75
- 77
- 79
then:
"sedmdesát pět, sedm, devět"
- else:
"neznámý"
!MATCH: Porovnávání vzorů¤
Typ: Mapping.
!MATCH
what: <what-expression>
with:
<value>: <expression>
<value>: <expression>
...
else:
<expression>
Výraz !MATCH vyhodnotí výraz what-expression, přiřadí hodnotu výrazu k klauzuli case a provede výraz expression spojený s tímto případem.
Větev else výrazu !MATCH je nepovinná.
Výraz selže s chybou, pokud není nalezena žádná odpovídající <value> a větev else chybí.
Příklad
!MATCH
what: !ARG value
with:
1: "jedna"
2: "dva"
3: "tři"
else:
"jiné číslo"
Použití !MATCH pro strukturování kódu
!MATCH
what: !ARG kód
with:
1: !INCLUDE code-1.yaml
2: !INCLUDE code-2.yaml
else:
!INCLUDE code-else.yaml
!TRY: Provádění operací dž do prvního bezchybného výrazu¤
Typ: Sequence
!TRY
- <expression>
- <expression>
- <expression>
...
Iteruje jednotlivými výrazy (odshora dolů), pokud výraz vrátí nenulový výsledek (None), zastaví iteraci a vrátí tuto hodnotu.
V opačném případě pokračuje k dalšímu výrazu.
Při dosažení konce seznamu vrátí None (chyba).
Poznámka: Zastaralý název tohoto výrazu byl !FIRST. Nepoužívá se od listopadu 2022.
!MAP: Použít výraz na každý prvek v posloupnosti¤
Typ: Mapping.
!MAP
what: <sequence>
apply: <expression>
Výraz apply se aplikuje na každý prvek v posloupnosti what s argumentem x obsahujícím příslušnou hodnotu prvku.
Výsledkem je nový seznam s transformovanými prvky.
Příklad
!MAP
whaz: [1, 2, 3, 4, 5, 6, 7]
apply:
!ADD [!ARG x, 10]
Výsledek je [11, 12, 13, 14, 15, 16, 17].
!REDUCE: Redukce prvků seznamu na jedinou hodnotu¤
Typ: Mapping.
!REDUCE
what: <expression>
apply: <expression>
initval: <expression>
fold: <left|right>
Výraz apply se aplikuje na každý prvek v posloupnosti what s argumentem a obsahujícím agregaci operace reduce a argumentem b obsahujícím příslušnou hodnotu prvku.
Výraz initval poskytuje počáteční hodnotu pro argument a.
Nepovinná hodnota fold určuje "levé skládání" (left, výchozí) nebo "pravé skládání" (right).
Příklad
!REDUCE
what: [1, 2, 3, 4, 5, 6, 7]
initval: -10
apply:
!ADD [!ARG a, !ARG b]
Vypočítá součet posloupnosti s počáteční hodnotou -10.
Výsledek je 18 = -10 + 1 + 2 + 3 + 4 + 5 + 6 + 7.
Výrazy pro datum a čas¤
Datum a čas se v SP-Langu vyjadřují pomocí typu datetime.
Má mikrosekundové rozlišení a rozsah od roku 8190 př.n.l. do roku 8191.
Je v časovém pásmu UTC.
Info
Další informace o typu datetime najdete zde.
!NOW: Aktuální datum a čas¤
Typ: Mapping.
Získá aktuální datum a čas.
!NOW
!DATETIME: Konstrukce data/času¤
Typ: Mapping.
Konstruuje datetime z komponent jako je rok, měsíc, den atd.
```yaml
!DATETIME
year: <year>
month: <month>
day: <day>
hour: <hour>
minute: <minute>
second: <second>
microsecond: <microsecond>
timezone: <timezone>
8191: * year je celé číslo v rozsahu -8190 ... 8191.
* month je celé číslo v rozsahu 1 ... 12.
* day je celé číslo v rozsahu 1 ... 31, odpovídající počtu dní v daném měsíci.
* hour je celé číslo v rozsahu 0 ... 24, je nepovinné a výchozí hodnota je 0.
* minute je celé číslo v rozsahu 0 ... 59, je nepovinné a výchozí hodnota je 0.
* second je celé číslo v rozsahu 0 ... 60, je nepovinné a výchozí hodnota je 0.
* microsecond je celé číslo v rozsahu 0 ... 1000000, je nepovinné a výchozí hodnota je 0.
* timezone je název časového pásma podle IANA Time Zone Database. Je nepovinný a výchozí časové pásmo je UTC.
Příklad: Datum/čas v UTC
!DATETIME
year: 2021
month: 10
day: 13
hour: 12
minute: 34
second: 56
microsecond: 987654
Příklad: výchozí hodnoty
!DATETIME
year: 2021
month: 10
day: 13
Příklad: časová pásma
!DATETIME
year: 2021
month: 10
day: 13
timezone: Europe/Prague
!DATETIME
year: 2021
month: 10
day: 13
timezone: "+05:00"
!DATETIME.FORMAT: Formátování data/času¤
Typ: Mapping.
Formátuje informace o datu a čase na základě datetime.
!DATETIME.FORMAT
with: <datetime>
format: <format>
timezone: <string>
datetime obsahuje informace o datech a čase, které se mají použít pro formátování.
formát je řetězec, který obsahuje specifikaci formátu výstupu.
Časové pásmo je nepovinná informace. Pokud je uvedena, bude čas vypsán v místním čase zadaném argumentem, jinak se použije časové pásmo UTC.
Formát¤
| Direktiva | Komponenta |
|---|---|
%H |
Hodiny (24hodinové hodiny) jako desetinné číslo doplněné nulou. |
%M |
Minuta jako desetinné číslo doplněné nulou. |
%S |
Vteřina jako desetinné číslo s nulovým znaménkem. |
%f |
Mikrosekunda jako desetinné číslo doplněné nulou na 6 číslic. |
%I |
Hodina (12hodinové hodiny) jako desetinné číslo doplněné nulou. |
%p |
Ekvivalent AM nebo PM v místním jazyce. |
%d |
Den v měsíci jako desetinné číslo s nulou. |
%m |
Měsíc jako desetinné číslo s nulou. |
%y |
Rok bez století jako desetinné číslo s nulou. |
%Y |
Rok se stoletím jako desetinné číslo. |
%z |
Posun UTC. |
%a |
Zkrácený název dne v týdnu. |
%A |
Den v týdnu jako plný název. |
%w |
Den v týdnu jako desetinné číslo, kde 0 je neděle a 6 je sobota. |
%b |
Měsíc jako zkrácený název. |
%B |
Měsíc jako plný název. |
%j |
Den v roce jako desetinné číslo s nulou. |
%U |
Číslo týdne v roce (neděle jako první den v týdnu) jako desetinné číslo s nulou. Všechny dny v novém roce předcházející první neděli se považují za dny v týdnu 0. |
%W |
Číslo týdne v roce (pondělí jako první den v týdnu) jako desetinné číslo s nulou. Všechny dny v novém roce předcházející prvnímu pondělí se považují za dny v týdnu 0. |
%c |
Reprezentace data a času. |
%x |
Reprezentace data. |
%X |
Reprezentace času. |
%% |
Doslovný znak '%'. |
Příklad
!DATETIME.FORMAT
with: !NOW
format: "%Y-%m-%d %H:%M:%S"
timezone: "Europe/Prague"
Vypíše aktuální místní čas jako např. 2022-12-31 12:34:56 s použitím časového pásma "Europe/Prague".
!DATETIME.PARSE: Parsování data/času¤
Typ: Mapping.
Parsuje datum a čas z řetězce.
!DATETIME.PARSE
what: <string>
format: <format>
timezone: <timezone>
Vstupní řetězec what analyzuje pomocí řetězce format.
Informace timezone je nepovinná. Pokud je uvedena, určuje místní časové pásmo řetězce what.
Další informace o řetězci format naleznete v kapitole Formát výše.
Příklad
!DATETIME.PARSE
what: "2021-06-29T16:51:43-08"
format: "%y-%m-%dT%H:%M:%S%z"
!GET: Získá komponentu datum/čas¤
Typ: Mapping.
Extrahuje z datetime komponenty data/času, jako je hodina, minuta, den atd.
!GET
what: <string>
from: <datetime>
timezone: <timezone>
Vybere komponentu what z datetime.
timezone je nepovinná, pokud není uvedena, použije se časová zóna UTC.
Komponenty¤
| Direktiva | Komponenta |
|---|---|
year, y |
Rok |
month, m |
Měsíc |
day, d |
Den |
hour, H |
Hodina |
minute, M |
Minuta |
second, S |
Sekunda |
microsecond, f |
Mikrosekunda |
weekday, w |
Den v týdnu |
Příklad
!GET
what: H
from: !NOW
timezone: "Europe/Prague"
Získá komponentu hours aktuálního časového razítka s použitím časového pásma "Europe/Prague".
Příklad: Aktuální rok
!GET { what: year, from: !NOW }
Slovníkové výrazy¤
Slovník (dict) uchovává kolekci dvojic (klíč, hodnota) tak, že každý možný klíč se v kolekci vyskytuje nejvýše jednou. Klíče ve slovníku musí být stejného typu, stejně jako hodnoty.
Položka je dvojice (klíč, hodnota) reprezentovaná jako tuple.
Nápověda
Tuto strukturu můžete znát pod alternativními názvy "asociativní pole" nebo "mapa".
!DICT: Dictionary¤
Typ: Mapping
!DICT
with:
<key1>: <value1>
<key2>: <value2>
<key3>: <value3>
...
Nápověda
Pro zjištění počtu položek ve slovníku použijte !COUNT.
Příklad
V jazyce SP-Lang lze slovník zadat několika způsoby:
!DICT
with:
key1: "One"
key2: "Two"
key3: "Three"
Implicitně zadaný slovník:
---
key1: "One"
key2: "Two"
key3: "Three"
```"Three"
Slovník zadaný zkráceně využívaje !!dict a flow stylu v YAML:
!!dict {key1: "One", key2: "Two", key3: "Three"}
Specifikace typu¤
Typ slovníku se označuje jako {Tk:Tv}, kde Tk je typ klíče a Tv je typ hodnoty.
Další informace o typu slovníku naleznete v příslušné kapitole v typovém systému.
Slovník se pokusí odvodit svůj typ na základě přidaných položek.
Typ první položky pravděpodobně poskytne typ klíče Tk a typ hodnoty Tv.
Pokud je slovník prázdný, jeho odvozený typ je {str:si64}.
Toto lze přepsat pomocí explicitní specifikace typu:
!DICT
type: "{str:any}"
with:
<key1>: <value1>
<key2>: <value2>
<key3>: <value3>
...
type je nepovinný argument obsahující řetězec se signaturou slovníku, která bude použita namísto odvozování typu z následníků.
Ve výše uvedeném příkladu je typ slovníku {str:any}, typ klíče je str a typ hodnot je any.
!GET: Získá hodnotu ze slovníku¤
Typ: Mapping.
!GET
what: <key>
from: <dict>
default: <value>
Získá hodnotu ze slovníku dict (slovník) identifikovaného pomocí key.
Pokud klíč není nalezen, vrátí default nebo chybu, pokud default není zadán.
default je nepovinné.
Příklad
!GET
what: 3
from:
!DICT
with:
1: "One"
2: "Two"
3: "Three"
Returns Three.
!IN: Test výskytu¤
Typ: Mapping.
!IN
what: <key>
where: <dict>
Zkontroluje, zda je key přítomen v dict.
Poznámka
Výraz !IN je popsán v kapitole Porovnávací výrazy.
Příklad
!IN
what: 3
where:
!DICT
with:
1: "One"
2: "Two"
3: "Three"
Direktivy¤
Note
Direktivy SP-Lang jsou při kompilaci rozšířeny. Nejsou to výrazy.
!INCLUDE: Vloží obsah jiného souboru¤
Typ: Skalární, Direktiva.
Direktiva !INCLUDE slouží k vložení obsahu daného souboru do aktuálního souboru.
Pokud není vkládaný soubor nalezen, SP-Lang zobrazí chybu.
Synopsis:
!INCLUDE <filename>
filename je název souboru v knihovně, který má být vložen.
Můžeme ho specifikovat pomocí:
- absolutní cesty začínající na
/z kořene knihovny, - relativní cesty k umístění souboru obsahujícího příkaz
!INCLUDE
Přípona .yaml je nepovinná a bude přidána ke jménu souboru, pokud chybí.
Příklad
!INCLUDE other_file.yaml
Jedná se o jednoduché začlenění souboru other_file.yaml.
!MATCH
what: !GET {...}
with:
'group1': !INCLUDE inc_group1
'group2': !INCLUDE inc_group2
V tomto příkladu se !INCLUDE používá k rozkladu většího výrazu na logicky oddělené soubory.
Výrazy pro funkce¤
!ARGUMENT, !ARG: Získá argument funkce¤
Typ: Scalar.
Synopsis:
!ARGUMENT name
!ARG name
Umožňuje přístup k argumentu name.
Tip
!ARG je zkrácená verze !ARGUMENT.
!FUNCTION, !FN: Definice funkce¤
Výraz !FUNCTION definuje novou funkci.
Obvykle se používá jako top-level expression.
Typ: Mapping.
Info
Výrazy SP-Lang jsou implicitně umístěné definice funkcí.
To znamená, že ve většině případů lze !FUNCTION přeskočit a je uvedena pouze sekce do.
Synopsis:
!FUNCTION
name: <name of function>
arguments:
arg1: <type>
arg2: <type>
...
returns: <type>
schemas: <dictionary of schemas>
do:
<expression>
Tip
!FN je zkrácená verze !FUNCTION.
Příklad
!FUNCTION
arguments:
a: si64
b: si32
c: si32
d: si32
returns: fp64
do:
!MUL
- !ARGUMENT a
- !ARGUMENT b
- !ARGUMENT c
- !ARGUMENT d
Tento výraz definuje funkci, která přijímá čtyři argumenty (a, b, c a d) s příslušnými datovými typy (si64, si32, si32 a si32) a vrací výsledek typu fp64.
Funkce vynásobí čtyři vstupní argumenty (a, b, c a d) a vrátí součin jako číslo s desetinou čárkou (fp64).
!SELF: Použije aktuální funkci¤
Příkaz !SELF umožňuje rekurzivně použít "self" alias aktuální funkci.
Typ: Mapping.
Synopsis:
!SELF
arg1: <value>
arg2: <value>
...
Poznámka
Výraz !SELF je tzv. Y kombinátor.
Příklad
!FUNCTION
argumenty: {x: int}
vrací: int
do:
!IF # hodnota <= 1
test: !GT [!ARG x, 1]
potom: !MUL [!SELF {x: !SUB [!ARG x, 1]}, !ARG x]
else: 1
Tento výraz definuje rekurzivní funkci, která přijímá jeden celočíselný argument x a vrací celočíselný výsledek.
Funkce vypočítá faktoriál vstupního argumentu x pomocí příkazu if-else.
Pokud je vstupní hodnota x větší než 1, funkce vynásobí x faktoriálem (x - 1), který vypočítá rekurzivním voláním sebe sama.
Pokud je vstupní hodnota x menší nebo rovna 1, funkce vrátí 1.
Výrazy pro IP adresy¤
IP adresy jsou interně reprezentovány jako 128bitová celá čísla bez znaménka. Takový typ může obsahovat jak IPv6, tak IPv4. IPv4 jsou mapovány do prostoru IPv6 pomocí RFC 4291 "IPv4-Mapped IPv6 Address".
!IP.FORMAT: Převádí IP adresu na řetězec¤
Typ: Mapping.
Synopsis:
!IP.FORMAT
what: <ip>
Převádí vnitřní reprezentaci IP adresy na řetězec.
!IP.INSUBNET: Zkontroluje, zda IP adresa spadá do podsítě¤
Typ: Mapping.
Synopsis:
!IP.INSUBNET
what: <ip>
subnet: <subnet>
!IP.INSUBNET
what: <ip>
subnet:
- <string>
- <string>
- <string>
Testuje, zda what IP adresa patří do subnet nebo podsítí, vrací true, pokud ano, jinak false.
Příklad s jednou podsítí
!IP.INSUBNET
what: 192.168.1.1
subnet: 192.168.0.0/16
Příklad s více podsítěmi
!IP.INSUBNET
what: 1.2.3.4
subnet:
- 10.0.0.0/8
- 172.16.0.0/12
- 192.168.0.0/16
Test, který kontroluje, zda adresa IP pochází z privátního adresního prostoru IPv4, jak je definováno v RFC 1918.
Kompaktní forma:
!IP.INSUBNET
what: 1.2.3.4
subnet: [10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16]
Parsování IP adresy¤
IP adresa je automaticky analyzována z řetězce.
V případě potřeby můžete IP adresu z řetězce explicitně převést na typ ip:
!CAST
type: ip
what: 192.168.1.1
Parsování podsítě IP¤
IP podsíť je automaticky parsována z řetězce.
V případě potřeby lze explicitně převést IP adresu z řetězce na typ ipsubnet:
!CAST
type: ipsubnet
what: 192.168.1.1/16
JSON¤
SP-Lang nabízí vysokorychlostní přístup k datovým objektům JSON.
!GET: Získá hodnotu z JSON¤
Typ: Mapping.
Synopsis:
!GET
what: <item>
typ: <type>
od: <json>
výchozí: <value>
Získat položku zadanou pomocí what z JSON objektu from.
Pokud položka není nalezena, vrátí default nebo chybu, pokud není zadáno default.
default je nepovinné.
Volitelně můžete zadat typ položky pomocí type.
Příklad
JSON (!ARG jsonmessage):
{
"foo.bar": "Příklad"
}
Pro získání pole foo.bar z výše uvedeného JSON:
!GET
what: foo.bar
from: !ARG jsonmessage
JSON Pointer¤
Pro přístup k položce ve vnořeném JSONu je třeba použít JSON Pointer (např. /foo/bar o/foo/bar) jako what.
Pro odvození typu položky se použije schéma, ale pro složitější přístup doporučujeme použít argument type.
Příklad
Vnořený JSON (!ARG jsonmessage):
{
"foo": {
"bar": "Příklad"
}
}
Příklad extrakce řetězce z vnořeného JSON:
!GET
what: /foo/bar
type: str
from: !ARG jsonmessage
!JSON.PARSE: Parsuje JSON¤
Typ: Mapping.
Synopsis:
!JSON.PARSE
what: <str>
schéma: <schema>
Parsuje JSON řetězec.
Výsledek lze použít např. pomocí operátoru !GET.
Nepovinný argument schema určuje schéma, které se má použít.
Výchozím schématem je vestavěné schéma ANY.
Příklad
!JSON.PARSE
what: |
{
"string1": "Hello World!",
"string2": "Goodby ..."
}
Výraz pro seznamy¤
Seznam (list) je jednou ze základních datových struktur, které SP-Lang nabízí. Seznam obsahuje konečný počet uspořádaných položek, přičemž stejná položka se může vyskytovat vícekrát. Položky v seznamu musí být stejného typu.
Poznámka
Seznam se někdy nepřesně nazývá také pole.
!LIST: Seznam položek¤
Typ: Implicit sequence, Mapping.
Synopsis:
!LIST
- ...
- ...
Nápověda
Pro určení počtu položek v seznamu použijte !COUNT.
Příklady¤
Existuje několik způsobů, jak lze v jazyce SP-Lang zadat seznam:
Example
!LIST
- "One"
- "Two"
- "Three"
- "Four"
- "Five"
Example
Formou mapování:
!LIST
with:
- "One"
- "Two"
- "Three"
- "Four"
- "Five"
!GET: Získá položku ze seznamu¤
Typ: Mapping.
Synopsis:
!GET
what: <index of the item in the list>
z: <list>
index je celé číslo (číslo).
index může být záporný, v tom případě určuje položku od konce seznamu.
Položky jsou indexovány od 0, to znamená, že první položka v seznamu má index 0.
Pokud je index mimo hranice seznamu, příkaz se vrátí s chybou.
Příklad
!GET
what: 3
from:
!LIST
- 1
- 5
- 30
- 50
- 80
- 120
Vrací hodnotu 50.
Příklad
!GET
what: -1
od:
!LIST
- 1
- 5
- 30
- 50
- 80
- 120
Vrací poslední položku seznamu, která je 120.
Logické výrazy¤
Logické výrazy se běžně používají k vytváření přísnějších a přesnějších podmínek, jako je filtrování událostí nebo spouštění konkrétních akcí na základě souboru kritérií.
Logické výrazy pracují s pravdivostními hodnotami true a false.
Logické výrazy jsou reprezentací logické algebry
Další informace naleznete na stránce boolean algebra na Wikipedii.
!AND: Konjunkce¤
Logický výraz !AND se používá ke spojení dvou nebo více podmínek, které musí být všechny pravdivé, aby byl celý výraz pravdivý.
Používá se k vytváření přísnějších a přesnějších podmínek.
Typ: Sequence
Synopsis:
!AND
- <condition 1>
- <condition 2>
- ...
V logickém výrazu !AND mohou být podmínky (podmínka 1, podmínka 2, ...) libovolné výrazy, které se vyhodnotí jako logická hodnota (true nebo false).
Podmínky jsou vyhodnocovány shora dolů a proces vyhodnocování se zastaví, jakmile je nalezena nepravdivá podmínka, podle konceptu zkratového vyhodnocování.
Logická konjunkce
Další informace naleznete na stránce Logická konjunkce na Wikipedii.
Příklad
!AND
- !EQ
- !ARG prodejce
- TeskaLabs
- !EQ
- !ARG produkt
- LogMan.io
- !EQ
- !ARG verze
- v23.10
V tomto příkladu, pokud se všechny podmínky vyhodnotí jako pravdivé, bude celý logický výraz !AND pravdivý.
Pokud je některá z podmínek nepravdivá, bude logický výraz !AND nepravdivý.
Bitové !AND¤
Pokud se !AND použije na celočíselné typy místo na logické, vytvoří se bitové AND.
Příklad
!AND
- !ARG PRI
- 7
V tomto příkladu je argument PRI maskován číslem 7 (binárně 00000111).
!OR: Disjunkce¤
Logický výraz !OR se používá ke spojení dvou nebo více podmínek, přičemž alespoň jedna z podmínek musí být pravdivá, aby byl celý výraz pravdivý.
Používá se k vytváření flexibilnějších a komplexnějších podmínek.
Typ: Sequence
Synopsis:
!OR
- <condition 1>
- <condition 2>
- ...
Podmínky (condition 1, condition 2, ...) mohou být libovolné výrazy, které se vyhodnotí jako logická hodnota (true nebo false).
Podmínky jsou vyhodnocovány shora dolů a proces vyhodnocování se zastaví, jakmile je nalezena pravdivá podmínka, podle konceptu zkráceného vyhodnocování.
Logická disjunkce
Další informace naleznete na stránce Logical disjunction na Wikipedii.
Příklad
!OR
- !EQ
- !ARG popis
- neoprávněný přístup
- !EQ
- !ARG důvod
- hrubá síla
- !EQ
- !ARG zpráva
- Zjištěn malware
V tomto příkladu je výraz pravdivý, pokud je splněna některá z následujících podmínek:
- Pole
descriptionodpovídá řetězci "unauthorized access". - Pole
reasonodpovídá řetězci "brute force". - Pole
messageodpovídá řetězci "malware detected".
Bitové !OR¤
Pokud se !OR použije na celočíselné typy místo na logické, poskytuje bitové OR.
Example
!OR
- 1 # Read access - přístup pro čtení (binární 001, desítková 1)
- 4 # Execute access - přístup pro spuštění (binárně 100, desítkově 4)
V tomto příkladu je výraz vyhodnocen jako 5.
Je to proto, že při bitové operaci !OR se každý odpovídající bit v binární reprezentaci obou čísel kombinuje pomocí výrazu !OR:
001 (přístup pro čtení)
100 (přístup pro spuštění)
---
101 (kombinovaná oprávnění)
Výraz vypočítá oprávnění s výslednou hodnotou (binární 101, desítková 5) z operace bitového OR, která kombinuje přístup ke čtení i ke spouštění.
!NOT: Negace¤
Logický výraz !NOT se používá k obrácení pravdivostní hodnoty podmínky.
Používá se k vyloučení určitých podmínek, pokud nejsou splněny jiné podmínky.
Typ: Mapping.
Synopsis:
!NOT
what: <expression>
Negace
Pro více informací pokračujte na stránku Negation na Wikipedii.
Bitové !NOT¤
Pokud je zadáno celé číslo, pak !NOT vrátí hodnotu s převrácenými bity what.
Tip
Pokud chcete otestovat, že celé číslo není nula, použijte testovací výraz !NE.
Vyhledávací výrazy¤
!LOOKUP: xxx¤
Typ: xxx Mapping.
!GET: Získá položku z vyhledávání¤
Typ: Mapping.
!IN: Zkontroluje, zda je položka v seznamu vyhledávání.¤
Typ: Mapping.
Výrazy pro PARSEC¤
Skupina výrazů PARSEC reprezentuje koncept Parser combinator.
Poskytuje způsob, jak kombinovat základní parsery za účelem konstrukce složitějších parserů na základě určitých pravidel. V tomto kontextu je parser funkce, která přijímá řetězec jako vstup a vytváří strukturovaný výstup, který indikuje úspěšné parsování nebo poskytuje chybové hlášení, pokud proces parsování selže.
Parsovací výrazy se dělí do dvou skupin: parsery a kombinátory.
Parsery lze považovat za základní jednotky nebo stavební bloky. Jsou zodpovědné za rozpoznávání a zpracování konkrétních vzorů nebo prvků ve vstupním řetězci.
Kombinátory jsou naproti tomu operátory nebo funkce, které umožňují kombinaci a skládání parserů.
Každý výraz pro parsování začíná předponou !PARSE..
!PARSE.DIGIT: Parsuje jednu číslici¤
Typ: Parser.
Synopsis:
!PARSE.DIGIT
Example
Vstupní řetězec: 2
!PARSE.DIGIT
!PARSE.DIGITS: Parsuje více číslic¤
Typ: Parser.
Synopsis:
!PARSE.DIGITS
min: <...>
max: <...>
exactly: <...>
Pole min, max a exactly jsou nepovinná.
Varování
Pole Exactly nelze použít společně s poli min nebo max. A samozřejmě hodnota max nesmí být menší než hodnota min.
Příklad
Vstupní řetězec: 123
!PARSE.DIGITS
max: 4
Další příklady
Parsování co nejvíce číslic:!PARSE.DIGITS
!PARSE.DIGITS
exactly: 3
!PARSE.DIGITS
min: 2
max: 4
!PARSE.LETTER: Parsuje jedno písmeno¤
Latinská písmena od A do Z, malá i velká písmena.
Typ: Parser.
Synopsis:
!PARSE.LETTER
Příklad
Vstupní řetězec: A
!PARSE.LETTER
!PARSE.CHAR: Parsuje jeden znak¤
Jakýkoli typ znaku.
Typ: Parser.
Synopsis:
!PARSE.CHAR
Příklad
Vstupní řetězec: @
!PARSE.CHAR
!PARSE.CHARS: Parsuje posloupnost znaků¤
Typ: Parser.
Synopsis:
!PARSE.CHARS
min: <...>
max: <...>
exactly: <...>
min, max a přesně jsou nepovinná.
Varování
Pole Exactly nelze použít společně s poli min nebo max. A samozřejmě hodnota max nesmí být menší než hodnota min.
Příklad
Vstupní řetězec: jméno@123_
!PARSE.CHARS
max: 8
Tip
Pro analýzu až do konce řetězce použijte !PARSE.CHARS bez polí.
Další příklady
Parsování co nejvíce znaků:!PARSE.CHARS
!PARSE.CHARS
exactly: 3
!PARSE.CHARS
min: 2
max: 4
!PARSE.SPACE: Parsuje jednu mezeru¤
Typ: Parser.
Synopsis:
!PARSE.SPACE
!PARSE.SPACES: Parsuje více mezer¤
Parsování co největšího počtu znaků mezery:
Typ: Parser.
Synopsis:
!PARSE.SPACES
!PARSE.ONEOF: Parsuje jeden znak z množiny znaků¤
Typ: Parser.
Synopsis:
!PARSE.ONEOF
what: <...>
!PARSE.ONEOF <...>
Příklad
Vstupní řetězec: Wow!
!PARSE.ONEOF
what: "!?"
!PARSE.NONEOF: Parsuje jeden znak, který není v množině znaků¤
Typ: Parser.
Synopsis:
!PARSE.NONEOF
what: <...>
!PARSE.NONEOF <...>
Příklad
Vstupní řetězec: Wow!
!PARSE.NONEOF
what: ",;:[]()"
!PARSE.UNTIL: Parsuje posloupnost znaků, dokud není nalezen konkrétní znak¤
Typ: Parser.
Synopsis:
!PARSE.UNTIL
what: <...>
stop: <before/after>
eof: <true/false>
!PARSE.UNTIL <...>
-
stop- určuje, zda se má znak stop analyzovat nebo ne. Možné hodnoty:beforeneboafter(výchozí). -
eof- udává, zda máme analyzovat až do konce řetězce, pokud není nalezen symbolwhat. Možné hodnoty:truenebofalse(výchozí).
Info
Pole `what` musí být jednoznakové. Lze však použít i některé bílé znaky, jako např. `tab`.
Příklad
Vstupní řetězec: 60290:11
!PARSE.UNTIL
what: ":"
Další příklady
Parsování až do symbolu: a zastavení před ním:
!PARSE.UNTIL
what: ":"
stop: "před"
!PARSE.UNTIL ' '
, symbol nebo do konce řetězce, pokud není symbol nalezen.
!PARSE.UNTIL
what: ","
eof: true
tab:
!PARSE.UNTIL
what: 'tab'
!PARSE.EXACTLY: Parsovat přesně definovanou posloupnost znaků¤
Typ: Parser.
Synopsis:
!PARSE.EXACTLY
what: <...>
nebo kratší verze:
!PARSE.EXACTLY <...>
Příklad
Vstupní řetězec: Hello world!
!PARSE.EXACTLY
what: "Hello"
!PARSE.BETWEEN: Parsuje posloupnost znaků mezi dvěma konkrétními znaky¤
Typ: Parser.
Synopsis:
!PARSE.BETWEEN
what: <...>
start: <...>
stop: <...>
escape: <...>
nebo kratší verze:
!PARSE.BETWEEN <...>
-
what- označuje, mezi kterými stejnými znaky máme provést parsování. -
start,stop- udává, mezi kterými různými znaky máme provést parsování. -
escape- označuje znak escape.
Příklad
Vstupní řetězec: [10/May/2023:08:15:54 +0000]
!PARSE.BETWEEN
start: '['
stop: ']'
Parsování mezi dvojitými uvozovkami:
!PARSE.BETWEEN
what: '"'
Parsování mezi dvojitými uvozovkami, zkrácená forma:
!PARSE.BETWEEN '"'
Parsování mezi dvojitými uvozovkami, přeskakuje interní dvojité uvozovky:
Vstupní řetězec:"jedna, "dva", tři"
!PARSE.BETWEEN
what: '"'
escape: '\'
!PARSE.REGEX: Parsuje posloupnost znaků, která odpovídá regulárnímu výrazu¤
Typ: Parser.
Synopsis:
!PARSE.REGEX
what: <...>
Příklad
Vstupní řetězec: FTVW23_L-C: Message...
Výstupní řetězec: FTVW23_L-C
!PARSE.REGEX
what: '[a-zA-Z0-9_\-0]+'
!PARSE.MONTH: Parsuje jméno měsíce¤
Typ: Parser.
Synopsis:
!PARSE.MONTH
what: <...>
nebo kratší verze:
!PARSE.MONTH <...>
what- udává formát názvu měsíce. Možné hodnoty:number,short,full.
Tip
Pomocí !PARSE.MONTH analyzujete název měsíce jako součást !PARSE.DATETIME.
Příklad
Vstupní řetězec: 10/May/2023:08:15:54
!PARSE.MONTH
what: 'short'
Další příklady
Parsování měsíce v číselném formátu:Vstupní řetězec:
2003-10-11
!PARSE.MONTH 'číslo'
Vstupní řetězec:
2003-OCTOBER-11
!PARSE.MONTH
what: 'full'
!PARSE.FRAC: Parsuje zlomek¤
Typ: Parser.
Synopsis:
!PARSE.FRAC
base: <...>
max: <...>
base- udává základ zlomku. Možné hodnoty:milli,micro,nano.max- udává maximální počet číslic v závislosti na hodnotěbase. Možné hodnoty:3,6,9.
Tip
Pomocí !PARSE.FRAC lze analyzovat mikrosekundy nebo nanosekundy jako součást !PARSE.DATETIME.
Příklad
Vstupní řetězec: Aug 22 05:40:14.264
!PARSE.FRAC
base: "micro"
max: 6
!PARSE.DATETIME: Parsování data v daném formátu¤
Typ: Parser.
Synopsis:
!PARSE.DATETIME
- year: <...>
- month: <...>
- day: <...>
- hour: <...>
- minute: <...>
- second: <...>
- nanosecond: <...>
- timezone: <...>
- Pole
month,dayjsou povinná. - Pole
yearje nepovinné. Pokud není zadáno, použije se funkce smart year. - Pole
hour,minute,second,microsecond,nanosecondjsou nepovinná. Pokud nejsou zadána, použije se výchozí hodnota 0. - Zadání pole mikrosekund jako
microsecond?, umožní parsovat mikrosekundy, pokud se vyskytují ve vstupním řetězci, a jinak ne. - Pole
timezoneje nepovinné. Pokud není zadáno, použije se výchozí hodnotaUTC. Lze jej zadat ve dvou různých formátech.Z,+08:00- analyzuje se ze vstupního řetězce.Evropa/Praha- zadáno jako konstantní hodnota.
Zkratky¤
K dispozici jsou tvary zkratek (v obou nižších/vyšších variantách):
!PARSE.DATETIME RFC3339
!PARSE.DATETIME iso8601
Příklad
Vstupní řetězec: 2022-10-13T12:34:56.987654
!PARSE.DATETIME
- year: !PARSE.DIGITS
- '-'
- month: !PARSE.MONTH 'číslo'
- '-'
- day: !PARSE.DIGITS
- 'T'
- hour: !PARSE.DIGITS
- ':'
- minute: !PARSE.DIGITS
- ':'
- second: !PARSE.DIGITS
- microsecond: !PARSE.FRAC
base: "micro"
max: 6
- timezone: "Europe/Prague"
Další příklady
Parsování data bez roku, s krátkým tvarem měsíce a volitelnými mikrosekundami:Vstupní řetězec:
Aug 17 06:57:05.189
!PARSE.DATETIME
- month: !PARSE.MONTH 'short' # Měsíc
- !PARSE.SPACE
- day: !PARSE.DIGITS # Den
- !PARSE.SPACE
- hour: !PARSE.DIGITS # Hodiny
- !PARSE.EXACTLY { what: ':' }
- minute: !PARSE.DIGITS # Minuty
- !PARSE.EXACTLY { what: ':' }
- second: !PARSE.DIGITS # Sekundy
- microsecond?: !PARSE.FRAC # Mikrosekundy
base: "micro"
max: 6
Vstupní řetězec:
2021-06-29T16:51:43+08:00
!PARSE.DATETIME
- year: !PARSE.DIGITS
- '-'
- month: !PARSE.MONTH 'číslo'
- '-'
- day: !PARSE.DIGITS
- 'T'
- hour: !PARSE.DIGITS
- ':'
- minute: !PARSE.DIGITS
- ':'
- second: !PARSE.DIGITS
- timezone: !PARSE.CHARS
Vstupní řetězec:
2021-06-29T16:51:43Z
!PARSE.DATETIME RFC3339
Vstupní řetězec:
20201211T111721Z
!PARSE.DATETIME iso8601
Vstupní řetězec:
2023-03-23T07:00:00.734323900
!PARSE.DATETIME
- year: !PARSE.DIGITS
- !PARSE.EXACTLY { what: '-' }
- month: !PARSE.DIGITS
- !PARSE.EXACTLY { what: '-' }
- day: !PARSE.DIGITS
- !PARSE.EXACTLY { what: 'T' }
- hour: !PARSE.DIGITS
- !PARSE.EXACTLY { what: ':' }
- minute: !PARSE.DIGITS
- !PARSE.EXACTLY { what: ':' }
- second: !PARSE.DIGITS
- nanosekunda: !PARSE.FRAC
base: "nano"
max: 9
Výrazy pro záznam¤
Záznam (record) je jednou ze základních datových struktur poskytovaných SP-Langem. Jedná se o kolekci položek, které mohou mít různé typy. Položky záznamu jsou pojmenovány (na rozdíl od tuple) pomocí štítku (label).
Poznámka
Záznam je postaven na !TUPLE.
!RECORD: Kolekce pojmenovaných položek¤
Typ: Mapping.
Synopsis:
!RECORD
with:
item1: <item 1>
item2: <item 2>
...
item1 a item2 jsou označení příslušných položek v záznamu.
Počet položek v záznamu není omezen. Pořadí položek je zachováno.
Příklad
!RECORD
with:
jméno: John Doe
věk: 37 let
výška: 175,4
Příklad ve flow-formě:
!RECORD {with: {jméno: John Doe, věk: 37 let, výška: 175,4} }
Použití tagu !!record:
{jméno: John Doe, věk: 37 let, výška: 175,4}
Example
Vynucení konkrétního typu položky:
!RECORD
with:
jméno: John Doe
věk: !!ui8 37
výška: 175,4
Pole age bude mít typ ui8.
!GET: Získá položku ze záznamu¤
Typ: Mapping.
Synopsis:
!GET
what: <name or index of the item>
from: <record>
Pokud je what řetězec, pak je to název pole v záznamu.
Pokud je what celé číslo, pak je to index v záznamu.
Hodnota what může být záporná, v takovém případě určuje položku z konce seznamu.
Položky jsou indexovány od 0, to znamená, že první položka v seznamu má index 0.
Pokud je what mimo hranice seznamu, příkaz se vrátí s chybou.
Příklad použití názvů položek:
!GET
what: name
from:
!RECORD
with:
jméno: John Doe
věk: 32 let
výška: 127,5
Vrátí John Doe.
Použití indexu položek:
!GET
what: 1
from:
!RECORD
- with:
name: John Doe
age: 32
height: 127.5
Vrací 32, hodnotu položky age.
Použití záporného indexu položek:
!GET
what: -1
from:
!RECORD
with:
name: John Doe
age: 32
height: 127.5
Vrací 127.5, hodnotu položky height.
Regexové výrazy¤
Tip
Pomocí Regexr můžete vytvářet a testovat regulární výrazy.
!REGEX: Vyhledávání pomocí regulárních výrazů¤
Typ: Mapping.
Synopsis:
!REGEX
what: <string>
regex: <regex>
hit: <hit>
miss: <miss>
Projde řetězec what a hledá libovolné místo, kde regulární výraz regex dává shodu.
Pokud je shoda nalezena, vrátí se hit, jinak se vrátí miss.
Výraz hit je nepovinný, výchozí hodnota je true.
Výraz miss je nepovinný, výchozí hodnota je false.
Příklad
```yaml !IF test: !REGEX what: "Hello world!" regex: "world" then: "Yes :-)" else: "No ;-("
```
Jiná forma:
!REGEX
what: "Hello world!"
regex: "world"
hit: "Ano :-)"
miss: "Ne ;-("
!REGEX.REPLACE: Nahrazení regulárním výrazem¤
Typ: Mapping.
Synopsis:
!REGEX.REPLACE
what: <string>
regex: <regex>
by: <string>
Nahradit regulární výraz regex odpovídající hodnotě what hodnotou by.
Example
!REGEX.REPLACE
what: "Hello world!"
regex: "world"
by: "Mars"
Vrací: Hello Mars!
!REGEX.SPLIT: Rozdělí řetězec pomocí regulárního výrazu¤
Typ: Mapping.
Synopsis:
!REGEX.SPLIT
what: <string>
regex: <regex>
max: <integer>
Dělí řetězec what regulárním výrazem regex.
Nepovinný argument max určuje maximální počet rozdělení.
Příklad
!REGEX.SPLIT
what: "07/14/2007 12:34:56"
regex: "[/ :]"
Vrací: ['07', '14', '2007', '12', '34', '56']
!REGEX.FINDALL: Najde všechny výskyty podle regulárního výrazu¤
Typ: Mapping.
Synopsis:
!REGEX.FINDALL
what: <string>
regex: <regex>
Najde všechny shody regex v řetězci what.
Příklad
!REGEX.FINDALL
what: "Frodo, Sam, Gandalf, Legolas, Gimli, Aragorn, Boromir, Smíšek, Pipin"
regex: \w+
Vrací: ['Frodo', 'Sam', 'Gandalf', 'Legolas', 'Gimli', 'Aragorn', 'Boromir', 'Smíšek', 'Pipin']
!REGEX.PARSE: Parsování pomocí regulárního výrazu¤
Type: Mapping.
Viz kapitolu !PARSE.REGEX
Výrazy pro práci s množinami¤
Množina (set) ukládá objekty zvané prvky, aniž by si všímala konkrétního pořadí, a každý prvek ukládá pouze jednou. Prvky v množině musí být stejného typu. Množina je jednou ze základních datových struktur poskytovaných jazykem SP-Lang.
Množina je vhodnější pro testování výskytu nějakého prvku spíše než pro získání konkrétního prvku.
!SET: množina prvků¤
Typ: Implicit sequence, Mapping.
Synopsis:
!SET
- ...
- ...
Nápověda
Pro určení počtu položek v sadě použijte !COUNT.
Existuje několik způsobů, jak lze v jazyce SP-Lang zadat množinu:
Příklad
!SET
- "One"
- "Dva"
- "Three"
- "Four"
- "Five"
Příklad
Kompaktní zápis množiny pomocí YAML flow sequences:
!SET ["One", "Two", "Three", "Four", "Five"]
Příklad
Formulář pro mapování:
!SET
with:
- "One"
- "Two"
- "Three"
- "Four"
- "Five"
!IN: Test členství¤
Typ: Mapping.
Synopsis:
!IN
what: <item>
where: <set>
Zkontroluje, zda je item přítomna v set.
Výraz !IN je popsán v kapitole Porovnávací výrazy.
Příklad
!IN
what: 3
where:
!SET
with:
- 1
- 2
- 5
- 8
Výrazy pro řetězce¤
!IN: Testuje, zda řetězec obsahuje podřetězec¤
Výraz !IN slouží ke kontrole, zda řetězec what je podřetězcem where, nebo ne.
Typ: Mapping.
Synopsis:
!IN
what: <...>
where: <...>
Pokud najde podřetězec what v řetězci where, vyhodnotí se jako true, v opačném případě jako false.
Příklad
!IN
what: "Willy"
kde: "John Willy Boo"
Zkontroluje přítomnost podřetězce "Willy" v hodnotě where. Vrátí hodnotu true.
Varianta pro více řetězců¤
Existuje speciální varianta operátoru !IN pro kontrolu, zda je některý z řetězců uvedených v hodnotě what (v tomto případě seznam) v řetězci. Jedná se o efektivní, optimalizovanou implementaci víceřetězcového matcheru.
!IN
what:
- "John"
- "Boo"
- "ly"
where: "John Willy Boo"
Jedná se o velmi efektivní způsob kontroly, zda je v řetězci where přítomen alespoň jeden podřetězec.
Podporuje Incremental String Matching algoritmus pro rychlé porovnávání vzorů v řetězcích.
Díky tomu je ideálním nástrojem pro komplexní filtrování jako samostatný bit nebo jako optimalizační technika.
Příklad optimalizace !REGEX pomocí víceřetězcového !IN:
!AND
- !IN
where: !ARG message
what:
- "msgbox"
- "showmod"
- "showhelp"
- "prompt"
- "write"
- "test"
- "mail.com"
- !REGEX
what: !ARG message
regex: "(msgbox|showmod(?:al|eless)dialog|showhelp|prompt|write)|(test[0-9])|([a-z]@mail\.com)
Tento přístup se doporučuje z aplikací v proudech, kde je třeba filtrovat rozsáhlé množství dat s předpokladem, že pouze menší část dat odpovídá vzorům.
Přímá aplikace výrazu !REGEX výrazně zpomalí zpracování, protože se jedná o složitý regulární výraz.
Jde o to "předfiltrovat" data jednodušší, ale rychlejší podmínkou tak, aby se k drahému !REGEX dostal jen zlomek dat.
Typické zlepšení výkonu je 5x-10x.
Z tohoto důvodu musí být !IN dokonalou nadmnožinou !REGEX, to znamená:
!IN->true,!REGEX->true:true!IN->true,!REGEX->false:false(to by měla být menšina případů).!IN->false,!REGEX->false:false(předfiltrování, mělo by se jednat o většinu případů)!IN->false,!REGEX->true: této kombinaci se MUSÍTE vyhnout, podle toho přijměte!INa/nebo!REGEX.
!STARTSWITH: Otestuje, zda řetězec začíná předponou¤
Vrací hodnotu true, pokud řetězec what začíná předponou prefix.
Typ: Mapping
Synopsis:
!STARTSWITH
what: <...>
prefix: <...>
Příklad
!STARTSWITH
what: "FooBar"
prefix: "Foo"
Víceřetězcová varianta¤
Work in progress
Zatím neimplementováno.
!STARTSWITH
what: <...>
prefix: [<prefix1>, <prefix2>, ...]
Ve víceřetězcové variantě je definován seznam řetězců.
Výraz se vyhodnotí jako true, pokud alespoň jeden prefixový řetězec odpovídá začátku řetězce what.
!ENDSWITH: Testuje, zda řetězec končí příponou¤
Vrací hodnotu true, pokud řetězec what končí příponou postfix.
Typ: Mapping
Synopsis:
!ENDSWITH
what: <...>
postfix: <...>
Příklad
!ENDSWITH
what: "autoexec.bat"
postfix: "bat"
Víceřetězcová varianta¤
Work in progress
Zatím neimplementováno.
!ENDSWITH
what: <...>
postfix: [<postfix1>, <postfix2>, ...]
Ve víceřetězcové variantě je definován seznam řetězců.
Výraz se vyhodnotí jako true, pokud alespoň jeden postfixový řetězec odpovídá konci řetězce what.
!SUBSTRING: Extrahuje část řetězce¤
Vrátí část řetězce what mezi indexy from a to.
Typ: Mapping
Synopsis:
!SUBSTRING
what: <...>
od: <...>
do: <...>
Info
První znak řetězce se nachází na pozici from=0.
Příklad
!SUBSTRING
what: "FooBar"
from: 1
do: 3
Vrací oo.
!LOWER: Převede řetězec na malá písmena¤
Typ: Mapping
Synopsis:
!LOWER
what: <...>
Příklad
!LOWER
what: "FooBar"
Vrací foobar.
!UPPER: Převede řetězec na velká písmena¤
Typ: Mapping
Synopsis:
!UPPER
what: <...>
Příklad
!UPPER
what: "FooBar"
Vrací FOOBAR.
!CUT: Vyjmout část řetězce¤
Rozdělí řetězec oddělovačem a vrátí část identifikovanou indexem field (začíná 0).
Typ: Mapping
Synopsis:
!CUT
what: <string>
delimiter: <string>
field: <int>
Řetězec argumentu value bude rozdělen pomocí argumentu delimiter.
Argument field určuje počet rozdělených řetězců, které se mají vrátit, počínaje 0.
Pokud je uveden záporný údaj field, pak se pole bere od konce řetězce, například -2 znamená předposlední podřetězec.
Příklad
!CUT
what: "Apple,Orange,Melon,Citrus,Pear"
delimiter: ","
field: 2
Vrátí hodnotu "Melon".
Příklad
!CUT
what: "Apple,Orange,Melon,Citrus,Pear"
delimiter: ","
field: -2
Vrátí hodnotu "Citrus".
!SPLIT: Rozdělí řetězec do seznamu¤
Rozdělí řetězec na seznam řetězců.
Typ: Mapping
Synopsis:
!SPLIT
what: <string>
oddělovač: <string>
maxsplit: <number>
Řetězec argumentu what bude rozdělen pomocí argumentu delimiter.
Nepovinný argument maxsplit určuje, kolik rozdělení se má provést.
Příklad
!SPLIT
what: "hello,world"
delimiter: ","
Výsledkem je seznam: ["hello", "world"].
!RSPLIT: Rozdělí řetězec do seznamu zprava¤
Rozdělí řetězec zprava (od konce řetězce) do seznamu řetězců.
Type: Mapping
Synopsis:
!RSPLIT
what: <string>
delimiter: <string>
maxsplit: <number>
Argument what se rozdělí podle delimeter. Nepovinný argument maxsplit určuje, kolik rozdělení se má provést.
!JOIN: Spojí seznam řetězců¤
Typ: Mapping
Synopsis:
!JOIN
items:
- <...>
- <...>
delimiter: <string>
miss: ''
Výchozí delimiter je mezera (" ").
Pokud je položka None, použije se hodnota parametru miss, ve výchozím nastavení je to prázdný řetězec.
Pokud je miss None a některá z položek items je None, výsledkem celého spojení je None.
Příklad
!JOIN
items:
- "Foo"
- "Bar"
delimiter: ','
Výrazy pro tuple¤
Tuple (do češtiny přeložitelné asi jako 'pevný seznam') je jednou ze základních datových struktur, které SP-Lang nabízí. Tuple je kolekce položek, které mohou mít různé typy.
!TUPLE: Kolekce položek¤
Typ: Mapping.
Synopsis:
!TUPLE
with:
- ...
- ...
...
Počet položek v tuple není omezen. Pořadí položek je zachováno.
Příklad
!TUPLE
with:
- John Doe
- 37
- 175.4
Příklad
Použití zápisu !!tuple:
!!tuple
- 1
- a
- 1.2
Příklad
Ještě stručnější verze !!tuple s použitím flow syntaxe:
!!tuple ['John Doe', 37, 175.4]
Příklad
Vynucení specifického typu položky:
!TUPLE
with:
- John Doe
- !!ui8 37
- 175.4
Položka #1 bude mít typ ui8.
!GET: Získá položku z tuple¤
Typ: Mapping.
Synopsis:
!GET
what: <index of the item>
from: <tuple>
what je celé číslo, které představuje index v tuple.
what může být záporné, v takovém případě určuje položku od konce seznamu.
Položky jsou indexovány od 0, to znamená, že první položka v seznamu má index 0.
Pokud je what mimo hranice seznamu, příkaz se vrátí s chybou.
Příklad
!GET
what: 1
from:
!TUPLE
with:
- Doe:: John Doe
- 32
- 127.5
Vrací 32.
Příklad
Použití záporného indexu položek:
!GET
what: -1
from:
!TUPLE
with:
- John Doe
- 32
- 127.5
Vrací 127,5.
Pomocné výrazy¤
!CAST: Převádí typ argumentu na jiný¤
Typ: Mapping.
Synopsis:
!CAST
what: <input>
typ: <type>
Explicitně převádí typ what na typ type.
SP-Lang automaticky převádí typy argumentů, takže uživatel nemusí na typy vůbec myslet. Tato funkce se nazývá implicit casting.
V případě potřeby explicitní konverze typu použijte výraz !CAST.
Jedná se o velmi mocnou metodu, která dělá hodně těžkou práci.
Další podrobnosti najdete v kapitole o typech.
Příklad
!CAST
what: "10.3"
type: fp64
Jedná se o explicitní převod řetězce na číslo s desetinnou čárkou.
!HASH: Vypočítá digest¤
Typ: Mapping.
Synopsis:
!HASH
what: <input>
seed: <integer>
typ: <type of hash>
Vypočítá hash pro hodnotu what.
seed určuje počáteční hash seed.
type určuje hašovací funkci, výchozí hodnota je XXH64.
Podporované hašovací funkce¤
XXH64: xxHash, 64bitový, nekryptografický, extrémně rychlý hashovací algoritmus.XXH3: xxHash, 64bit, nekryptografický, optimalizovaný pro malé vstupy
Více informací o xxHash naleznete na adrese xxhash.com.
Příklad
!HASH
what: "Hello world!"
seed: 5
!DEBUG: Ladění výrazů¤
Vypíše obsah vstupu a na výstupu předá nezměněnou hodnotu.
Typ: Mapping.
Ended: Výrazy
Jazyk ↵
Podrobnosti o typech kontejnerů¤
List (seznam)¤
List je uspořádaný seznam konečného počtu položek, přičemž stejná položka se může vyskytovat vícekrát.

Set (množina)¤
Set je složen z Interního seznamu (Internal list) a hašovací tabulky.

Dict (slovník)¤
dict je kombinací množiny (která je složena z hašovací tabulky a seznamu) klíčů (nazývané Key set s Key list ) a seznamu hodnot (nazývaného Value list).

Hash table (hašovací tabulka)¤
Typy Set a Dict používají hash table.

Hash table je navržena tak, že mapuje 64bitový hash klíče přímo na index položky. Podporuje strategii perfect hash, takže pro zkonstruovanou hašovací tabulku není implementováno žádné řešení kolizí. Pokud algoritmus pro konstrukci hašovací tabulky zjistí kolizi, algoritmus se znovu spustí s jinou hodnotou seed. Tento přístup využívá relativně vysokou míru kolizí xxhash64.
Hašovací tabulku lze generovat pouze tehdy, když je to potřeba (např. pro výrazy !IN a !GET).
To platí pro objekty vytvářené dynamicky za běhu.
Statické množiny a slovníky poskytují připravenou hašovací tabulku.
Hašovací tabulka se prohledává pomocí binárního vyhledávání.
Použité hašovací funkce jsou:
- XXH3 64bit se seedem pro
str. xorse seedem prosi64,si32,si16,si8,ui64,ui32,si16,ui8
SP-Lang datum/čas¤
Typ datetime je hodnota, která reprezentuje datum a čas v UTC s použitím struktury zvané "broken time".
To znamená, že rok, měsíc, den, hodina, minuta, sekunda a mikrosekunda jsou uloženy ve vyhrazených polích; liší se např. od UNIX timestamp.
- Časové pásmo: UTC
- Rozlišení: mikrosekundy (šest desetinných míst)
Užitečné nástroje
* [UNIX Timestamp](https://www.unixtimestamp.com)
* [Převodník UTC na/z místního času](https://www.worldtimebuddy.com)
Rozložení bitů¤
Datum je uloženo v 64bitovém celočíselném formátu bez znaménka (ui64); little-endian formát, nativní pro Intel/AMD 64bit.

| Pozice | Komponenta | Bity | Maska | Typ* | Rozsah | Poznámka |
|---|---|---|---|---|---|---|
| 58-63 | 4 | 0...15 | OK (0)/Chybný (8)/Vyhrazeno | |||
| 46-57 | rok | 14 | si16 |
-8190...8191 | ||
| 42-45 | měsíc | 4 | 0x0F | ui8 |
1...12 | Indexováno od 1 |
| 37-41 | den | 5 | 0x1F | ui8 |
1...31 | Indexováno od 1 |
| 32-36 | hodina | 5 | 0x1F | ui8 |
0...24 | |
| 26-31 | minuta | 6 | 0x3F | ui8 |
0...59 | |
| 20-25 | druhý | 6 | 0x3F | ui8 |
0...60 | 60 je pro přestupnou sekundu |
| 0-19 | mikrosekunda | 20 | ui32 |
0...1000000 |
Poznámka
*) Typ je doporučený/minimální typ zarovnaný na bajty pro příslušnou komponentu.
Podrobnosti o časovém pásmu¤
Informace o časových pásmech pocházejí z pytz, resp. z IANA Time Zone Database.
Note
Databáze časových pásem má přesnost na minuty, to znamená, že sekundy a mikrosekundy zůstávají při převodu z/do UTC nedotčeny _.
Data o časových pásmech jsou reprezentována adresářovou strukturou souborového systému, která je běžně umístěna na adrese /usr/share/splang nebo na místě určeném proměnnou prostředí SPLANG_SHARE_DIR.
Skutečná data časových pásem jsou uložena v podsložce tzinfo.
Data časových pásem jsou generována skriptem generate_datetime_timezones.py během instalace SPLangu.
Příklad složky tzinfo
```
.
└── tzinfo
├── Evropa
│ ├── Amsterdam.sptl
│ ├── Amsterdam.sptb
│ ├── Andorra.sptl
│ ├── Andorra.sptb
```
Soubory .sptl a .sptb obsahují rychlostně optimalizované binární tabulky, které podporují rychlé vyhledávání pro převody místního času <-> UTC.
Soubor .sptl je určen pro little-endian architektury procesorů (x86 a x86-64), soubor .sptb je určen pro big-endian architektury.
Soubor je memory-mapped do paměťového prostoru procesu SP-Lang, zarovnaný na 64bajtovou hranici, takže jej lze přímo použít jako vyhledávač.
Běžné struktury¤
ym: Rok a měsíc,ym = (year << 4) + monthdhm: Den, hodina a minuta,dhm = (day << 11) + (hour << 6) + minute
Obě struktury jsou bitovými částmi skalární hodnoty datetime a lze je z datetime extrahovat pomocí AND a SHR.**
Záhlaví souboru časových pásem¤
Délka záhlaví v 64 bajtech.
Neurčené bajty jsou nastaveny na 0 a rezervovány pro budoucí použití.
- Pozice
00...03:SPt/ magický identifikátor - Pozice
04:<for little-endian CPU architecture,>pro big-endian - Pozice
05: Verze (v současné době1ASCII znak) - Pozice
08...09: Minimální rok/měsíc (min_ym) v tomto souboru, měsíc MUSÍ BÝT 1 - Pozice
10...11: Maximální rok/měsíc (min_ym) v tomto souboru - Pozice
12...15: Pozice "tabulky parseru" v souboru, vynásobená 64, obvykle1, protože tabulka parseru je uložena přímo za záhlavím.
Tabulka parseru časových pásem¤
Tabulka parser table je vyhledávací tabulka používaná pro převod místního data/času na UTC.
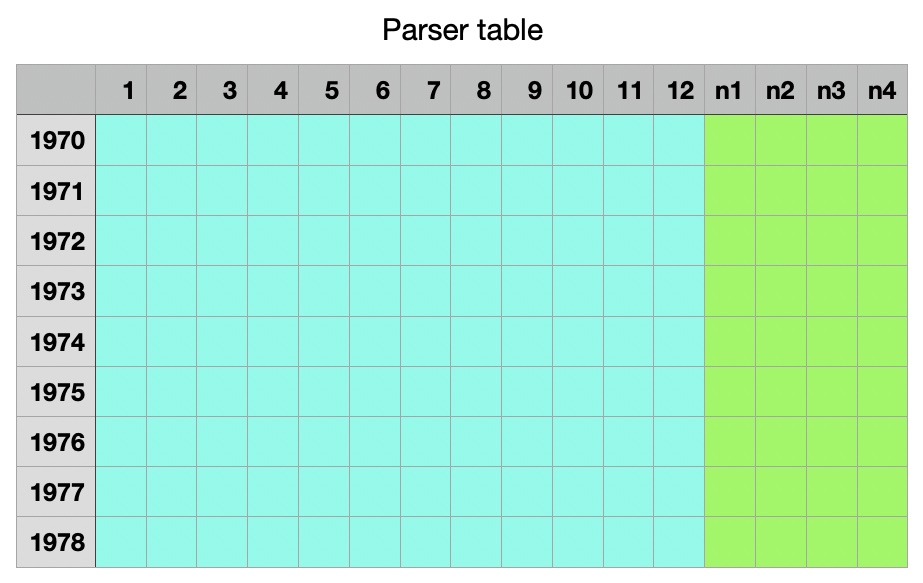
Tabulka je uspořádána do řádků/let a sloupců/měsíců. Buňka je široká 4 bajty, řádek je pak dlouhý 64 bajtů.
Prvních 12 buněk jsou "primární buňky parseru" (ve světle modré barvě), jejich počet odráží číslo měsíce (1...12).
Zbývající 4 buňky jsou "další buňky parseru", číslo nX je index.
Primární buňka parseru¤
Pozice buňky pro dané datum/čas se vypočítá jako pos = (ym - min_ym) << 5, což znamená, že pro lokalizaci buňky se použije rok a měsíc minus minimální hodnota roku&měsíce pro tabulku.
Struktura buňky:
* 16 bitů: rozsah, 16bitů, dhm
* 3 bity: next
* 7 bitů: hodinový posun od UTC
* 6 bitů: minutový posun od UTC
dhm označuje den, hodinu a minutu v roce/měsíci, kdy dochází ke změně času (např. začátek/konec letního času).
Pro typický měsíc - kdy není pozorována žádná změna času - představuje hodnota dhm maximum v daném měsíci.
Pokud je dhm pro vstupní datum/čas matematicky nižší než dhm z primární buňky, pak se informace hodina a minuta použijí k úpravě data/času z místního na UTC.
Pokud je dhm větší, pak next obsahuje číslo "další buňky parseru"; nachází se na konci příslušného řádku tabulky parseru.
Další buňka parseru¤
Buňka "parser next" obsahuje "pokračování" informace pro měsíc, ve kterém je pozorována změna času. "Pokračování" znamená posun od UTC, ke kterému dojde, když místní čas překročí hranici změny času.
Struktura buňky:
* 16 bitů: rozsah, 16bitů, dhm
* 3 bity: nepoužívají se, nastaví se na 0
* 7 bitů: hodinový posun od UTC
* 6 bitů: minutový posun od UTC
dhm označuje den, hodinu a minutu v roce/měsíci, kdy je pozorována DALŠÍ změna času (např. začátek/konec letního času).
Protože v současné době podporujeme pouze jednu změnu času v měsíci, je toto pole nastaveno na maximální hodnotu dhm pro daný měsíc.
Informace hodina a minuta slouží k úpravě data/času z místního na UTC.
Poznámka
V současné době je podporována pouze jedna změna času v měsíci, což se zdá být plně dostačující pro všechny informace v databázi časových zón IANA.
Prázdné/nepoužité další buňky jsou vynulovány.
Chyby¤
Pokud je nastaven bit 63 datetime, pak hodnota data/času představuje chybu.
Výraz, který tuto hodnotu vytvořil, pravděpodobně nějakým způsobem selhal.
Kód chyby je uložen v dolních 32 bitech.
Design jazyka SP-Lang¤
Vlastnosti¤
- Deklarativní jazyk
- Funkční jazyk
- Silně typovaný jazyk
- Odvozování typů
- Syntaxe je založena na YAMLu
Kompilace anebo interpretace
SP-Lang je:
📜 Deklarativní¤
Většina počítačových jazyků je imperativní. To znamená, že většina kódu směřuje k tomu, aby počítači vysvětlila, jak má provést nějakou úlohu. Naproti tomu SP-Lang je deklarativní. Tvůrce popisuje, "co" chce, aby jeho logika udělala, nikoliv přesně "jak" nebo "kdy" to má být provedeno. Překladač pak vymyslí, jak to provést. To kompilátoru umožňuje silně optimalizovat tím, že odkládá práci, dokud není potřeba, předem načítá a znovu používá data z mezipaměti atd.
🔗 Funkční¤
SP-Lang upřednostňuje čisté funkce bez vedlejších efektů. Výsledkem je logika, která je srozumitelnější a dává kompilátoru největší volnost při optimalizaci.
🔀 Bezstavový¤
Neexistuje žádný stav, který by bylo možné modifikovat, a proto nejsou žádné proměnné, pouze konstanty. Data procházíte různými výrazy a sestavujete konečný výsledek.
Více informací
🔐 Silně typovaný¤
Typy všech hodnot jsou známy v době kompilace. To umožňuje včasné odhalení chyb a posílení optimalizace.
💡 Podpora odvozování typů¤
Typy jsou odvozeny z jejich použití, aniž by byly deklarovány. Například nastavení proměnné na číslo vede k tomu, že typ této proměnné je stanoven jako číslo. To dále snižuje složitost pro tvůrce bez oběti na výkonu známé z interpretovaných jazyků.
Pro pokročilé uživatele, kteří vyžadují větší kontrolu nad typovým systémem, poskytuje SP-Lang mechanismy pro explicitní určení typů nebo interakci s typovým systémem v případě potřeby. Tato flexibilita umožňuje pokročilým uživatelům vyladit svůj kód pro maximální výkon a spolehlivost a zároveň využívat pohodlí typové inference.
🎓Turingovsky úplný¤
SP-Lang je navržen tak, aby byl turingovsky úplný.
Správa paměti¤
Správa paměti v SP-Langu je založena na konceptu paměťových arén - memory arenas.

Diagram: Rozložení paměťových arén
Paměťová aréna je předem alokovaný větší kus paměti, který je k dispozici pro daný životní cyklus (tj. jeden cyklus zpracování události). Když nějaký kód související se zpracováním událostí potřebuje paměť, požádá o kousek z paměťové arény. Tento kousek je poskytnut rychle, protože je vždy odebrán ze začátku volného místa v aréně (tzv. offset). Rozdělení proběhne najednou pro celou arénu. Mluvíme o tzv. "resetu" paměťové arény. To znamená, že koncept paměťové arény je velmi efektivní, nezavádí fragmentaci paměti a dobře se kombinuje s konceptem statického jedinečného přiřazení SP-Langu.
Paměťová aréna také podporuje seznam destruktorů, který umožňuje integraci s tradičními např. malloc alokacemi pro technologie třetích stran, které nejsou kompatibilní s paměťovou arénou (např. knihovna PCRE2).
Destruktory se provádějí při resetu arény.
Paměťová aréna může být rozšířena o další paměťový chunk, pokud je aktuální chunk vyčerpán.
Výkon jazyka SP-Lang¤
Úvod¤
SP-Lang je navržen tak, aby poskytoval velmi vysoký výkon.
Interně kompiluje poskytnuté výrazy do strojového kódu pomocí LLVM IR a velkého stupně optimalizací, které jsou možné díky funkcionální struktuře jazyka. Nabízí extrémně vysokou propustnost jednoho jádra procesoru s bezproblémovou schopností škálovat zpracování podle dostupných jader procesoru a plně využívat výhod moderních architektur procesorů.
Výkonnostní testy měří propustnost v EPS, událostech za sekundu. Události za sekundu je termín používaný ve správě IT pro definici počtu událostí, které jsou zpracovány výrazem SP-Lang za jednu sekundu. EPS se měří pro jedno jádro procesoru.
Výkonnostní testy jsou automatizovány pomocí rámce CI/CD, a proto jsou zcela reprodukovatelné.
Porovnávání více řetězců¤
Tento výraz vyhledává prvky konečné množiny řetězců ve vstupním textu. Hodí se např. pro klasifikaci škodlivých adres URL (poskytnutých blokovým seznamem) ve výstupu firewallu.
!IN
where: !ARG url
what:
- ".000a.biz"
- ".001edizioni.com"
< 64 domains in total >
- ".2win-tech.com"
- ".2zzz.ru"
- Jádro jednoho procesoru na
HW-M1-20: 1423686 EPS - Jedno jádro CPU na
HW-I7-15: 807685 EPS
Parsování JSON¤
!JSON.PARSE
what: |
{
< https://github.com/TeskaLabs/cysimdjson/blob/main/perftest/jsonexamples/test.json >
}
Poznámka
Rychlé parsování JSON je zajištěno projekty cysimdjson, resp. simdjson._.
- Jedno jádro procesoru na
HW-M1-20: 968502 EPS - Jedno jádro CPU na
HW-I7-15: 562862 EPS
Parsování IETF Syslogu¤
Toto je parser IETF Syslog aka RFC5424 implementovaný v SP-Langu:
# Hlavička
- !PARSE.EXACTLY {what: '<'}
- !PARSE.DIGITS
- !PARSE.EXACTLY {what: '>'}
- !PARSE.DIGITS
- !PARSE.EXACTLY {what: ' '}
- !PARSE.TUPLE # Časové razítko
- !PARSE.DIGITS # Rok
- !PARSE.EXACTLY {what: '-'}
- !PARSE.DIGITS # Měsíc
- !PARSE.EXACTLY {what: '-'}
- !PARSE.DIGITS # Den
- !PARSE.EXACTLY {what: 'T'}
- !PARSE.DIGITS # Hodiny
- !PARSE.EXACTLY {what: ':'}
- !PARSE.DIGITS # Minuty
- !PARSE.EXACTLY {what: ':'}
- !PARSE.DIGITS # Sekundy
- !PARSE.EXACTLY {what: '.'}
- !PARSE.DIGITS # Subsekundy
- !PARSE.EXACTLY {what: 'Z'}
- !PARSE.EXACTLY {what: ' '} # HOSTNAME
- !PARSE.UNTIL {what: ' '}
- !PARSE.EXACTLY {what: ' '} # APP-NAME
- !PARSE.UNTIL {what: ' '}
- !PARSE.EXACTLY {what: ' '} # PROCID
- !PARSE.UNTIL {what: ' '}
- !PARSE.EXACTLY {what: ' '} # MSGID
- !PARSE.UNTIL {what: ' '}
- !PARSE.EXACTLY {what: ' '} # STRUCTURED-DATA
- !PARSE.OPTIONAL
what: !PARSE.TUPLE
- !PARSE.EXACTLY {what: '['}
- !PARSE.UNTIL {what: ' '} # SD-ID
- !PARSE.REPEAT
what:
!PARSE.TUPLE # SD-PARAM
- !PARSE.EXACTLY {what: ' '}
- !PARSE.UNTIL {what: '='} # PARAM-NAME
- !PARSE.EXACTLY {what: '='}
- !PARSE.BETWEEN
what: '"'
escaped: '\\"]'
- Jádro jednoho procesoru na
HW-M1-20: 304004 EPS - Jedno jádro CPU na
HW-I7-15: 181494 EPS
Referenční hardware¤
HW-M1-20¤
- Stroj: MacBook Air (M1, 2020)
- CPU: Apple M1, uveden na trh v roce 2020
HW-I7-15¤
- Stroj: MacBook Pro (15palcový, 2016)
- CPU: I7-6700HQ, uveden na trh v roce 2015.
Schéma¤
Schémata v SP-Langu popisují typ a další vlastnosti polí v dynamicky typovaných kontejnerech, jako je JSON nebo pythonovské slovníky.
Je důležité poskytnout SP-Langu informace o typu, protože se používají jako vstup pro typovou inferenci, a tedy pro optimální výkon.
Definice schématu¤
Reprezentace schématu ve formátu YAML:
---
define:
type: splang/schema
fields:
field1:
type: str
aliases: ["FieldOne"]
field2:
type: ui64
Možnosti¤
Možnost type¤
Definuje datový typ daného atributu, například str, si64 a podobně.
Další informace naleznete v typovém systému SP-Langu.
Tato volba je povinná.
Možnost aliases¤
Definuje aliasy polí pro daný atribut, které lze použít v deklaraci jako synonymní výraz.
Pokud má pole field1 alias pole s názvem FieldOne, jsou následující deklarace rovny, pokud je schéma správně definováno:
!GET
what: field1
from: !ARG input
!GET
what: FieldOne
from: !ARG input
Možnost unit¤
Definuje jednotku atributu, pokud je potřeba, například pro časové značky. V tomto případě může být jednotka auto pro automatickou detekci, sekundy a mikrosekundy.
Deklarace funkce (Python)¤
Příklad deklarace funkce SP-Lang, která používá MYSCHEMA.yaml:
splang.FunctionDeclaration(
name="main",
returns="bool",
arguments={
'myArgument': 'json<MYSCHEMA>'
},
)
a samotný soubor MYSCHEMA.yaml:
---
define:
type: splang/schema
fields:
field1:
type: str
field2:
type: ui64
In-place schémata¤
SP-Lang umožňuje specifikovat schéma přímo v kódu FunctionDeclaration jazyka Python:
splang.FunctionDeclaration(
name="main",
returns="bool",
arguments={
'myArgument': 'json<INPLACESCHEMA>'
},
schemas=[
("INPLACESCHEMA", {
"field1": "str",
"field2": "si32",
"field3": "ui64",
})
]
)
Provádí se pomocí tuple, první položka je název schématu, druhá je slovník s poli.
Řetězce¤
Řetězce v SP-Langu používají kódování UTF-8.
Reprezentace typu řetězce je str.
Reprezentace řetězce¤
Řetězec je reprezentován P-Stringem příslušným záznamem s následujícími položkami:
- Délka řetězce v bajtech jako 64bitové číslo bez znaménka.
- Pointer na začátek řetězcových dat.
Řetězec je také pole bajtů
Hodnota str je binárně kompatibilní s [ui8], seznamem ui8.
Kompatibilita s řetězci ukončenými nulou¤
Hodnota str NESMÍ končit znakem \0 (NULL).
Dodatečné \0 může být umístěno hned za údaji řetězce, ale nesmí být zahrnuto do délky řetězce.
Zajišťuje přímou kompatibilitu se systémy NULL-terminated string.
Není však implicitně zaručena pomocí str.
NULL ukončený řetězec lze "převést" na str vytvořením nového str pomocí strlen() a skutečného ukazatele na data řetězce.
Alternativně lze vytvořit i úplnou kopii.
Data řetězce¤
Data řetězce je paměťový prostor, který obsahuje skutečnou hodnotu řetězce.
Řetězcová data mohou být:
- umístit hned za strukturu
str - zcela samostatný řetězcový buffer ("string view")
Řetězcová data mohou být sdílena s mnoha strukturami str, včetně odkazů na části řetězcových dat (tzv. podřetězce).
Datové typy SP-Lang¤
V SP-Langu hraje typový systém zásadní roli při zajišťování správnosti a efektivity provádění výrazů. SP-Lang používá typovou inferenci. To znamená, že typový systém pracuje v zákulisí a poskytuje vysoký výkon, aniž by uživatele zatěžoval svou složitostí. Tento přístup umožňuje bezproblémové a uživatelsky přívětivé prostředí, kde mohou pokročilí uživatelé přistupovat k typovému systému pro jemnější kontrolu a optimalizaci.
Info
Systém typů je soubor pravidel, která definují, jak se v jazyce klasifikují, kombinují a manipulují datové typy. Pomáhá včas zachytit potenciální chyby, zvyšuje spolehlivost kódu a zajišťuje, aby se operace prováděly pouze nad kompatibilními datovými typy.
Skalární typy¤
Skalární typy jsou základními stavebními kameny jazyka, které reprezentují jednotlivé hodnoty. Jsou nezbytné pro práci s různými druhy dat a provádění různých operací.
Celá čísla¤
Celá čísla jako například -5, 0 nebo 42, která lze použít pro počítání nebo jednoduché aritmetické operace. Celá čísla mohou být se znaménkem nebo bez znaménka.
|Typ|Jméno|Typ|Jméno|Bity|Bajty|.
|:----|:----|:----|:----|:----|:----|
|si8|Signed 8bit integer|ui8|Unsigned 8bit integer|8|1|
|si16|Podepsané 16bitové celé číslo|ui16|Nepodepsané 16bitové celé číslo|16|2|
|si32|Signed 32bit integer|ui32|Unsigned 32bit integer|32|4|
|si64|Signed 64bit integer|ui64|Unsigned 64bit integer|64|16|
|si128|Signed 128bit integer|ui128|Unsigned 128bit integer|128|32|
|si256|Podepsané 256bitové celé číslo|ui256|Nezapsané 256bitové celé číslo|256|64|
Preferovaným (výchozím) typem celého čísla je si64 (64bitové celé číslo se znaménkem), následované ui64 (64bitové celé číslo bez znaménka).
Je to proto, že SP-Lang je primárně určen pro 64bitové procesory.
int je alias pro si64.
Varování
256bitové velikosti zatím nejsou plně podporovány.
Pravdivostní hodnoty (boolean)¤
Boolean (bool, pravdivostní hodnota) je typ, který má jednu ze dvou možných hodnot označených jako True a False.
Desetinná čísla (floats)¤
Desetinná čísla, například 3,14 nebo -0,5, jsou užitečná pro výpočty zahrnující zlomky nebo přesnější hodnoty.
| Typ | Název | Bajtů |
|---|---|---|
fp16 |
16bit float | 2 |
fp32 |
32bit float | 4 |
fp64 |
64bit float | 8 |
fp128 |
128bit float | 16 |
Varování
fp16 a fp128 nejsou plně podporovány.
Varování
Alias float se překládá na fp64, který se překládá na LLVM double (odlišný od aliasu float).
Komplexní skalární typy¤
Komplexní skalární typy jsou určeny pro hodnoty, které poskytují nějakou vnitřní strukturu (technicky vzato jsou to tedy záznamy (records) nebo tuples), ale mohou se vejít do skalárního typu (např. z důvodu výkonu nebo optimalizace).
Datum/čas¤
datetime
Jedná se o hodnotu, která reprezentuje datum a čas v UTC s využitím struktury "broken time".
Broken time znamená, že rok, měsíc, den, hodina, minuta, sekunda a mikrosekunda jsou uloženy ve vyhrazených polích; liší se např. od časového razítka UNIX.
- Časové pásmo: UTC
- Rozlišení: mikrosekundy (šest desetinných míst)
- 64bitové celé číslo bez znaménka, také známé jako
ui64
Zlomené časové komponenty
y/yearm/měsícd/dayH/hourM/minutaS/sekundau/mikrosekunda
Podrobnější popis data/času je zde.
IP adresy¤
Tento datový typ obsahuje adresu IPv4 nebo IPv6.
ip
Základní skalární typ: ui128
RFC 4291
IPv4 jsou mapovány do prostoru IPv6, jak je předepsáno v RFC 4291 "IPv4-Mapped IPv6 Address".
Generické typy¤
Generické typy se používají v počáteční fázi parsování, optimalizace a kompilace SP-Langu. Doplňujícím typem je Specifický typ. SP-Lang převádí generické typy na specifické typy pomocí mechanismu zvaného type inference. Pokud generický typ nelze převést na specifický, kompilace selže a je třeba poskytnout další informace pro typovou inferenci.
Generický typ začíná velkým písmenem T.
Také pokud typ kontejneru obsahuje generický typ, je samotný kontejnerový typ nebo strukturální typ považován za generický.
Typy kontejnerů¤
List (seznam)¤
[Ti]
Tioznačuje typ položky v seznamu
List musí obsahovat nulu, jednu nebo více položek stejného typu.
Typem konstruktoru je výraz !LIST.
Set (množina)¤
{Ti}
Tiodkazuje na typ položky v množině
Typem konstruktoru je výraz !SET.
Dictionary (slovník)¤
{Tk:Tv}
Tkodkazuje na typ klíčeTvoznačuje typ hodnoty
Konstruktor typu je výraz !DICT.
Bag¤
[(Tk,Tv)]
Tkodkazuje na typ klíčeTvoznačuje typ hodnoty
Bag (neboli multimap) je kontejner, který umožňuje duplicitní klíče, na rozdíl od slovníku, který umožňuje pouze jedinečné klíče.
Tip
Bag je v podstatě seznamem 2 dvojic (párů).
Produktové typy¤
Produktový typ je složený typ, který vznikne spojením jiných typů do struktury.
Tuple¤
Signatura: (T1, T2, T3, ...)
Konstruktor typu je výraz !TUPLE.
Je ekvivalentní strukturnímu typu v LLVM IR.
Tip
Tuple bez členů respektive () je jednotka.
Record (záznam)¤
Signatura: (name1: T1, name2: T2, name3: T3, ...)
Typem konstruktoru je výraz !RECORD.
Je ekvivalentní výrazu struct jazyka C.
Sum (součtový typ)¤
Typ Sum je datová struktura používaná k uchování hodnoty, která může nabývat několika různých typů.
Any (libovolný typ)¤
any
Typ any je speciální typ, který představuje hodnotu, která může mít libovolný typ.
Varování
Typ any by neměl být používán jako preferovaný typ, protože má režijní náklady.
Přesto je poměrně užitečný při psaní slovníku, který kombinuje typy (např. {str:any}), a v dalších situacích, kdy typ hodnoty není při kompilaci znám.
Hodnota obsažená v typu any je vždy umístěna v paměti (např. v paměťovém fondu); z tohoto důvodu je tento typ pomalejší než ostatní, které hodnotu ukládají přednostně do registrů procesoru.
Typ any je rekurzivní typ; může obsahovat sám sebe, protože obsahuje všechny ostatní typy v typovém univerzu.
Z tohoto důvodu nelze vypočítat obecnou nebo dokonce maximální velikost proměnné any.
Objektové typy¤
String (řetězec)¤
str
Musí být v kódování UTF-8.
Poznámka
str může být předáván do [ui8] (seznam ui8) způsobem 'toll-free'; jedná se o binární ekvivalent.
Bajty¤
Work in progress
Plánované.
Enum¤
"Work in progress
Plánované.
Regex¤
regex
Obsahuje zkompilovaný vzor regulárního výrazu.
Pokud je vzor regexu konstantní, je zkompilován v době kompilace příslušného výrazu. V případě dynamického regexového vzoru probíhá kompilace regexu během vyhodnocování výrazu.
JSON¤
json<SCHEMA>
JSON objekt, výsledek parsování JSON. Jedná se o typ založený na schématu.
Typ funkce¤
Funkce¤
(arg1:T1,arg2:T2,arg3:T3)->Tr
T1,T2,T3jsou typy vstupů funkcíarg1,arg2aarg3.Trudává typ výstupu funkce
Pythonovské typy¤
Pythonovské typy jsou objektové typy, které poskytují rozhraní s jazykem Python.
Python Dictionary¤
pydict<SCHEMA>
Slovník Pythonu. Jedná se o typ založený na schématu.
Python Object¤
pyobj
Obecný Python objekt.
Python List¤
pylist
Seznam Python.
Python Tuple¤
pytuple
Casting¤
Pro změnu typu hodnoty použijte výraz !CAST.
!CAST
what: 1234
typ: fp32
nebo ekvivalentní zkratka:
!!fp32 1234
Poznámka
Cast je také skvělým pomocníkem pro typovou inferenci, to znamená, že jej lze v případě potřeby použít k explicitnímu určení typu.
Typy založené na schématu¤
Schema je koncept SP-Langu, jak propojit systémy bez schémat, jako je JSON nebo Python, se silně typizovaným SP-Langem. Schéma je v podstatě adresář, který mapuje pole na jejich typy atd. Další informace najdete v kapitole o SP-Langu schémata.
Typ založený na schématu SP-Lang specifikuje schéma pomocí jména schématu: json<SCHEMANAME>.
Název schema slouží k vyhledání definice schématu např. v knihovně.
Seznam typů založených na schématu:
* pydict<...>
* json<...>
Vestavěná (build-in) schémata¤
ANY: Toto schéma deklaruje, že každý člen je typuany.VOID: Toto schéma nemá žádný člen, pro určení typů polí použijte definici typu na místě.
Ended: Jazyk
Vizuální programování ↵
Vizuální programování v jazyce SP-Lang¤
SP-Lang umožňuje uživatelům vytvářet výrazy pomocí grafické manipulace s prvky výrazu, nikoli jejich textovým zadáním.
Příklad parseru Syslogu implementovaného ve vizuálním SP-Langu: